- Փ������:
- 0
|
<DIV>
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515749f0m1.png" target=_blank></A>ժҪ</P>
<P style="TEXT-INDENT: 2em">�҂��O(sh��)Ӌ���F(xi��n)��google�ļ�ϵ�y(t��ng)���һ�������Ҏ(gu��)ģ�ֲ�ʽ��(sh��)��(j��)�ܼ��ԑ�(y��ng)�õĿɔUչ�ֲ�ʽ�ļ�ϵ�y(t��ng)�����\�������r����Ʒ��Ӳ�����ṩ���e����������������Ŀ͑����ṩ�ߵ����w���������� </P>
<P style="TEXT-INDENT: 2em">�M���c�F(xi��n)�еķֲ�ʽ�ļ�ϵ�y(t��ng)���кܶ���ͬ��Ŀ�������҂����O(sh��)Ӌ����ā�Դ�ڌ����҂��ľ��w��(y��ng)�õ�ؓ�d����Լ���(d��ng)ǰ����δ�����g(sh��)�h(hu��n)�����^��������@��ʹ�����c���ڵ��ļ�ϵ�y(t��ng)���F(xi��n)�����@�IJ�ͬ������@Ҳʹ���҂�����ҕ���y(t��ng)�ϵ��O(sh��)Ӌ�x��̽����һЩ�ڸ����ϲ�ͬ���O(sh��)Ӌ�^�c������</P>
<P style="TEXT-INDENT: 2em"> �@���ļ�ϵ�y(t��ng)�ɹ��ĝM�����҂��Ĵ惦�����������S�@�о����_�l(f��)��Ŭ�����������google��(n��i)����������ѽ�(j��ng)������Щ��Ҫ��(sh��)��(j��)������(w��)�Ĕ�(sh��)��(j��)����̎���Ļ��A(ch��)�惦ƽ�_���V����������������ֹ���������ļ�Ⱥ����ͨ�^���^һǧ�_�C���Ĕ�(sh��)ǧ�KӲ�P�ṩ��(sh��)��T�Ĵ惦������@Щ�惦���g�����ɔ�(sh��)�ق��͑��˲��l(f��)�L�����</P>
<P style="TEXT-INDENT: 2em"> �ڱ�Փ����������҂�����������֧�ֲַ�ʽ��(y��ng)�õ��ļ�ϵ�y(t��ng)�Uչ�ӿ��O(sh��)Ӌ�����ӑՓ�ܶ��҂����O(sh��)Ӌ�^�c��չʾ������beachmark�ͬF(xi��n)�������һЩ�y����(sh��)��(j��)�������</P>
<P style="TEXT-INDENT: 2em"> ������}�������ֲ�ʽ�ļ�ϵ�y(t��ng) </P>
<P style="TEXT-INDENT: 2em"> �����~���O(sh��)Ӌ������ɿ��������������������y��</P>
<P style="TEXT-INDENT: 2em"> �P(gu��n)�I�~�����e��������ɔUչ��������(sh��)��(j��)�惦�����Ⱥ�惦</P>
<P style="TEXT-INDENT: 2em"> ��(d��o)��</P>
<P style="TEXT-INDENT: 2em">���˝M��google�������L�Ĕ�(sh��)��(j��)̎�������҂��O(sh��)Ӌ���F(xi��n)��google�ļ�ϵ�y(t��ng)(GFS)����GFS�c���y(t��ng)�ķֲ�ʽ�ļ�ϵ�y(t��ng)���кܶ���ͬ��Ŀ�˱��������������ɔUչ�ԣ��ɿ������������������Ȼ���������O(sh��)Ӌ�����҂��ľ��w��(y��ng)�õ�ؓ�d����Լ���(d��ng)ǰ����δ�����g(sh��)�h(hu��n)�����^���(q��)�ӵ�������������c�����ļ�ϵ�y(t��ng)���O(sh��)Ӌ���O(sh��)�������@�ą^(q��)�e���҂�����ҕ���y(t��ng)�ϵ��O(sh��)Ӌ�x���������̽����һЩ�ڸ����ϲ�ͬ���O(sh��)Ӌ�^�c�������</P>
<P style="TEXT-INDENT: 2em"> һ�������M��ʧ���ɞ�һ�N���B(t��i)�����Ǯ������ļ�ϵ�y(t��ng)���ɳɰ���ǧ�_ͨ�^���r����Ʒ�������M�b�����Ĵ惦�C����(g��u)�����������Ա������Ŀ͑����L�����M���Ĕ�(sh��)�����|(zh��)���ڱ��|(zh��)�ϛQ������ijһ�r�g��һЩ�Dz����õ������һЩ�o���Į�(d��ng)ǰ��ʧ���л֏�(f��)�^�����҂��^�쵽��������(y��ng)�ó����bug������ϵ�y(t��ng)bug������˞���e�`����Ӳ�P��ʧ�����������(n��i)��������B�������W(w��ng)�j(lu��)����������(y��ng)�����������@�ӵĆ��}����˽�(j��ng)���ԵıO(ji��n)�������e�`�z�y��������e���Ԅӻ֏�(f��)��횼��ɵ�ϵ�y(t��ng)������</P>
<P style="TEXT-INDENT: 2em"> ������c���y(t��ng)�Ę˜������������ļ��Ǿ����������@�������Îׂ�G���ļ��Ǻ���ͨ�����ÿ���ļ�ͨ�������ܶ�đ�(y��ng)�ó���̎���Č������W(w��ng)��ęn���������(d��ng)�҂�?n��i)ճ�̎���Ŀ������L�Ĕ�(sh��)��(j��)���Ͽ����_���Îׂ�TB�Ĵ�С���������(sh��)ʮ�|�Č���r��ȥ̎�픵(sh��)ʮ�|��KB���e���ļ���ʹ�ļ�ϵ�y(t��ng)֧��Ҳ���@�úܱ�������@���O(sh��)Ӌ�е�һЩ���O(sh��)�ͅ���(sh��)������IO�����͉K��С�ͱ�����¶��x�������</P>
<P style="TEXT-INDENT: 2em">��������ֵ��ļ�����ģʽ��ͨ�^��β���Ӕ�(sh��)��(j��)�����Ǹ��w�F(xi��n)�Д�(sh��)��(j��)�����ļ���(n��i)�����S�C���������Dz����ڵ�������һ�����������ļ�����ֻ�x�����������ͨ��������x������������Ĕ�(sh��)��(j��)�������@�ӵ����c������Щ�����DZ���(sh��)��(j��)�����������Ď�M��������Щ���������\���еđ�(y��ng)�ó�����m(x��)���ɵĔ�(sh��)��(j��)�������Щ�����Ǚn����(sh��)��(j��)����Щ�����ǔ�(sh��)��(j��)��Ҫ��һ�_�C���a(ch��n)�����Ȼ������һ�_�C��̎�����a(ch��n)�������g�Y(ji��)�������O(sh��)�ڴ��ļ��ϔ�(sh��)��(j��)�L�������@�ӵ�ģʽ���������ô��(d��ng)��(d��ng)���攵(sh��)��(j��)�ڿ͑���ʧЧ�������append�����ͳɞ����܃�(y��u)����ԭ���Ե��P(gu��n)�I����</P>
<P style="TEXT-INDENT: 2em"> ���������(y��ng)�ó�����ļ�ϵ�y(t��ng)api�ąf(xi��)ͬ�O(sh��)Ӌ������������ϵ�y(t��ng)���`���ԡ������҂�ͨ�^������GFS��һ����ģ�ʹ�����ļ�ϵ�y(t��ng)�������ͬ�rҲ�]�нo��(y��ng)�ó������ص�ؓ��(d��n)����҂�Ҳ�ṩ��һ��ԭ���Ե�append����������@�Ӷ����͑��˾Ϳ��Ԍ�ͬһ���ļ����е��M��append����������Ҫ�˴��g�M���~���ͬ��������������@Щ�����ں����M��Ԕ����ӑՓ����</P>
<P style="TEXT-INDENT: 2em"> Ŀǰ�ѽ�(j��ng)�ж���GFS��Ⱥ���˲�ͬ��Ŀ�Ķ������������������ǂ�����1000���惦��(ji��)�c���������^300T�ĴűP���g��������Բ�ͬ�C���Ĕ�(sh��)�ق��͑��˳��m(x��)�L������</P>
<P style="TEXT-INDENT: 2em"> 2 �O(sh��)Ӌ���[</P>
<P style="TEXT-INDENT: 2em">2.1 ���O(sh��)</P>
<P style="TEXT-INDENT: 2em">���O(sh��)Ӌһ���M���҂�������ļ�ϵ�y(t��ng)�r��������҂���һЩ��M������(zh��n)�͙C���ļ��O(sh��)����ָ���������֮ǰ�҂����g�ӵ��ᵽ�^һЩ�P(gu��n)�I���c���F(xi��n)���҂����@Щ���O(sh��)��Ԕ�����г����������</P>
<P style="TEXT-INDENT: 2em"> ϵ�y(t��ng)�������r�Ľ�(j��ng)��ʧ������Ʒ���M����(g��u)�����������������M�н�(j��ng)���ԵıO(ji��n)�غ͙z�y�������e�����������܉�ĽM��ʧ����Ѹ�ٵĻ֏�(f��)���@Щ����(y��ng)ԓ�������й����������</P>
<P style="TEXT-INDENT: 2em"> ϵ�y(t��ng)�惦���m�Ȃ���(sh��)�Ĵ��ļ�����҂������Д�(sh��)���f���ļ���ÿ��100mb���߸�����������GB���ļ���С��(y��ng)ԓ�Ǻ���ͨ����r�����ܱ���Ч�Ĺ��������С�ļ�Ҳ��(y��ng)ԓ��֧�֣����҂�����Ҫ�������M�Ѓ�(y��u)�����</P>
<P style="TEXT-INDENT: 2em"> ����ؓ�d��Ҫ�ɃɷN��͵��x�M�ɣ���������ʽ�xȡ��С���S�C�xȡ�������ڴ����ʽ�xȡ�У�������ͨ��Ҫ�xȡ��(sh��)��k����������1m���߸���Ĕ�(sh��)��(j��)��������ͬһ���͑��˵��B�m(x��)�xȡ������ͨ���x���ļ���һ���B�m(x��)�^(q��)��С���S�C�xȡͨ����ij�������ƫ��λ���xȡ��kb�Ĕ�(sh��)��(j��)��������������R�đ�(y��ng)�ó�������@ЩС���S�C�xȡ�����Σ�����ʹ���xȡ���Է�(w��n)���Ĵ�Խ�����ļ������ǁ����xȡ�������</P>
<P style="TEXT-INDENT: 2em"> ����ؓ�d�кܶ��Č��ļ���(sh��)��(j��)��append���������ͨ�������Ĵ�С����c�x�����������һ������������ͺ��ٸ�׃�����ļ���(n��i)�����S�C���������Ա�֧���������������ܲ����Ǻܸߵġ�</P>
<P style="TEXT-INDENT: 2em"> ϵ�y(t��ng)�������ö��x�Ķ����͑��ˌ���ͬ�ļ��IJ���append��������ṩ��Ч�Č��F(xi��n)�����҂����ļ�ͨ�����Á��������a(ch��n)�����M����л����M�ж�·�w��������(sh��)�ق����a(ch��n)��(ÿ���C�����\��һ��)������ͬһ���ļ��M��append���������˾�����С��ͬ���_�N��ԭ�����DZ�Ҫ���������ļ�֮����ܕ����xȡ���������M�߿��ܲ��е��xȡ�@���ļ������</P>
<P style="TEXT-INDENT: 2em"> �ߵij��m(x��)�����ȵ��ӕr����Ҫ�����҂��ֵ�Ŀ�ˑ�(y��ng)�ö�ϣ���õ����ٵ�������(sh��)��(j��)̎���ٶ���������Ќ��چ����x���Ї����푑�(y��ng)�r�g����</P>
<P style="TEXT-INDENT: 2em"> 2.2�ӿ�</P>
<P style="TEXT-INDENT: 2em">GFS�ṩһ����Ϥ���ļ�ϵ�y(t��ng)�ӿ���������M�������]�Ќ��F(xi��n)һ���T��POSIX�ǘӵĘ˜�API�����ļ�ͨ�^Ŀ��M�ЌӴλ��M������ͨ�^·������R�ļ�����֧�ֳ�Ҋ����Щ�ļ�������create,delete,open,close,read,write�������</P>
<P style="TEXT-INDENT: 2em"> �����������GFS߀���п��պ�append������������������Ժܵ͵��_�N��(chu��ng)��һ���ļ�����Ŀ䛔�(sh��)�Ŀ�ؐ������Append�������S�����͑�����ͬһ���ļ����l(f��)�IJ����������ͬ�r���Cÿ�������͑��˵�append������ԭ�����������@���ڌ��F(xi��n)��·�w���ĽY(ji��)���Լ����������M����к��Ў������@�ӿ͑��˲���Ҫ�~����i�����Ϳ��Բ��е�append����҂��l(f��)�F(xi��n)�@�N�ļ���ͣ����ژ�(g��u)�����͵ķֲ�ʽ��(y��ng)�ú�ֱ���ǟo�r֮����������������պ�append����������3.4��3.3�քeӑՓ��</P>
<P style="TEXT-INDENT: 2em"> 2.3�ܘ�(g��u)</P>
<P style="TEXT-INDENT: 2em">һ��GFS��Ⱥ��һ��master�Ͷ���chunkserver�M�����������Ա�����client�L��������D1��ʾ�������</P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">��������һ���\�����Ñ�������(w��)�M�̵���Ʒ��linux�C�������������Ժ�������ͬһ�_�C�����\��һ��chunkserver��client����ֻҪ�C���YԴ���S�Լ������\�п��ܵ�Ƭ�(y��ng)�ó�����a�����ĵͿɿ����ǿ��Խ��ܵ����</P>
<P style="TEXT-INDENT: 2em"> �ļ������ֳɹ̶���С��chunk��ÿ��chunk����chunk��(chu��ng)���r��master�����һ������׃��ȫ��Ψһ��64bit�������R������Chunkserver��chunk����linux�ļ��惦�ڱ��������������chunk��(sh��)��(j��)���x��ͨ�^chunk��handle���ֹ�(ji��)߅�����ʾ��������˿ɿ������ÿ��chunk�惦�ڶ���chunkserver�ϡ��M���Ñ����Ԟ鲻ͬ�ļ����ֿ��g�^(q��)��ָ����ͬ�Ă�ݼ��e���Ĭ�J���҂��惦������ݡ�</P>
<P style="TEXT-INDENT: 2em"> Master�S�o���е��ļ�ϵ�y(t��ng)Ԫ��(sh��)��(j��)�������������ֿ��g���L��������Ϣ��������ļ��cchunk��ӳ����Ϣ���chunk�Į�(d��ng)ǰλ���������Ҳ����ϵ�y(t��ng)������(n��i)��һЩ����������chunk���U�������������chunk�������������chunkserver�g��chunk�w�����Master�cchunkserverͨ�^������Ϣ�M�������Ե�ͨ�ţ��l(f��)��ָ����ռ�chunkserver�Ġ�B(t��i)���</P>
<P style="TEXT-INDENT: 2em">��(y��ng)�ó���朽ӵ�GFS�͑��˴��a���F(xi��n)���ļ�ϵ�y(t��ng)API�Լ����푪(y��ng)�ó����cmaster��chunkserver�M��ͨ�����x����(sh��)��(j��)�������������͑��������Ҫ����Ԫ��(sh��)��(j��)�t��Ҫ�cmasterͨ���������������еļ���(sh��)��(j��)ͨ��ֱ���cchunkseverͨ����������҂��]���ṩPOSIX API�����Ҳ�Ͳ���Ҫ�clinux vnode layer�P(gu��n)(li��n)������</P>
<P style="TEXT-INDENT: 2em"> �͑��˻���chunkserver�������M���ļ���(sh��)��(j��)�����������͑��˾���ֻ�ܵõ����ٵĺ�̎���������ֵđ�(y��ng)����Ҫֱ���xȡ�������ļ����߹�������̫������o������������]��cache�����˿͑��˺�����ϵ�y(t��ng)����鲻��Ҫ���]����һ���Ԇ��}(���H�Ͽ͑��˕�����Ԫ��(sh��)��(j��))�������Chunkserver����Ҫ�M���ļ���(sh��)��(j��)���������������chunk�����鱾���ļ��惦���@��linux���������Щ��(j��ng)���L���Ĕ�(sh��)��(j��)�M�о���������</P>
<P style="TEXT-INDENT: 2em"> 2.4 ��Master</P>
<P style="TEXT-INDENT: 2em"> ֻ��һ��master������҂����O(sh��)Ӌ�����������ʹ��master��������ȫ����Ϣ��chunk�ķ��ú͂���M�и��õ��Д�����Ȼ��������҂������С�������x���еą��c�������ʹ���������ɞ�һ��ƿ�i������Client���h����ͨ�^master�xȡ�ļ���(sh��)��(j��)�����ֻ�dž�master����(y��ng)ԓͬ�Ă�chunkserver(li��n)ϵ������client���@Щ��Ϣ�����ĕr�g��(n��i)�M�о������ֱ���cchunksever�����M�кܶ���m(x��)�IJ�����</P>
<P align=center><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515171uP3t.png" target=_blank><IMG height=253 src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515171uP3t.png" width=588 border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em"> ����(j��)�D1�������҂����ν��һЩһ���x�����Ľ����^�̣����ȣ�ͨ�^�̶���С��chunk�������͑��ˌ���(y��ng)�ó����И��R���ļ�����offset�D(zhu��n)�Q��chunk��index��Ȼ��omaster�l(f��)��һ�������ļ�����chunk index��Ո�����master��������(y��ng)��chunk��handle�����Ђ�ݵ�λ�á�����͑������ļ�����chunk index��key���@�l��Ϣ�M�о�������</P>
<P style="TEXT-INDENT: 2em"> Ȼ��͑��˽o����һ����ݰl(f��)��һ��Ո��ͨ����������ǂ�����Ո����R��chunk ��handle�Լ����ǂ�chunk��(n��i)���ֹ�(ji��)߅�硣ֱ��������Ϣ�^�ڻ������´��_�ļ�֮ǰ�������������ͬchunk�ĺ��m(x��)�x�����Ͳ���Ҫclient-master��ͨ����������ϣ��͑���ͨ����һ��Ո���в�ԃ����chunk����Ϣ����masterҲ���Ԍ��@Щ��Ո��Ķ���chunk����Ϣ������һ�K�M�з����������@�N�e����Ϣ�����]���~��Ļ��M�ͱ�����δ����client-master�Ķ��ͨ�����</P>
<P style="TEXT-INDENT: 2em"> 2.5 chunk��С</P>
<P style="TEXT-INDENT: 2em">Chunk��С��һ���P(gu��n)�I���O(sh��)Ӌ����(sh��)���҂��x����64mb������h�h���ڬF(xi��n)�е��ļ�ϵ�y(t��ng)�K������ÿ��chunk�ĸ���������ͨ��linux�ļ��惦��chunkserver����������Ҫ�ŕ��M�ДUչ��Lazy���g��������˃�(n��i)����Ƭ��ɵĿ��g���M��������ܿ���������Ƭ����һ��chunk��ô��</P>
<P style="TEXT-INDENT: 2em"> ���chunk size�ṩ�ˎׂ���Ҫ�ă�(y��u)����������������������client�csever�Ľ��������������ͬchunk�ϵ��x��ֻ��Ҫһ����ʼ��Ո��Ϳ��ԏ�master�õ�chunk��λ����Ϣ����@���p�ٌ����҂��đ�(y��ng)��ؓ�d�Ƿdz����@�ģ�����҂���(y��ng)�ô���Ҫ�����x���������ļ������ʹ����С���S�C�xȡ���͑���Ҳ���Ժ����ľ���һ����TB������������chunk��λ����Ϣ������������������chunk�ܴ������ô�͑��˾ͺ��п�����һ���o����chunk�ψ�(zh��)�и���IJ������@�ӿ��Ԍ�һ���cchunkserver��TCP�B�ӱ��ָ��L�ĕr�g�����@�͜p���˾W(w��ng)�j(lu��)�_�N�����������������˴惦��master�ϵ�Ԫ��(sh��)��(j��)��С����@�Ӿ����S�҂���Ԫ��(sh��)��(j��)����ڃ�(n��i)���У����^���͎������҂�����2.6.1��ӑՓ��������(y��u)������</P>
<P style="TEXT-INDENT: 2em"> ��һ�����������chunk size�����ʹ������lazy���g�������Ҳ������ȱ�c��С���ļ�����ֻ���ٔ�(sh��)�ׂ�chunk������Sֻ��һ����������ܶ��client����Ҫ�L���@���ļ����@����Щ�惦���@Щchunk��chunkserver�͕�׃�ɟ��c����������H������������c߀�]�гɞ�һ����Ҫ�Ŀ��]�c����҂��đ�(y��ng)�ý^�ֶ���������x��Ķ�chunk�ļ���</P>
<P style="TEXT-INDENT: 2em"> Ȼ����������(d��ng)GFS��һ��ʹ����һ����̎�����ϵ�y(t��ng)�r�����c�_�����F(xi��n)�ˣ�һ���Ɉ�(zh��)���ļ�����һ��chunk���ļ�����GFS�����Ȼ��ͬ�r�ڔ�(sh��)���_�C�����_ʼ��(zh��)�С��惦��ԓ�Ɉ�(zh��)���ļ�����Щchunkserver����(sh��)�ق����l(f��)Ո��˲�g׃�ɳ��d�����҂�ͨ�^���ߵĂ�ݼ��e�惦�@�ӵĿɈ�(zh��)���ļ��Լ��p�����ϵ�y(t��ng)�đ�(y��ng)�ó��ӕr�g��Q���@�����}���һ�����ڵ��L�h�Ľ�Q���������@�N��r�£����S�͑��ˏ������͑����xȡ��(sh��)��(j��)�����</P>
<P style="TEXT-INDENT: 2em"> 2.6Ԫ��(sh��)��(j��)</P>
<P style="TEXT-INDENT: 2em">Master�惦��������Ҫ��͵�Ԫ��(sh��)��(j��)���ļ���chunk���ֿ��g�������ļ���chunk��ӳ����Ϣ������ÿ��chunk�Ă�ݵ�λ�á����е�Ԫ��(sh��)��(j��)��������master�ă�(n��i)�������ǰ�ɷN���߀ͨ�^�����²�������־�����ڱ���Ӳ�P�͂�����h�̙C�������ֳ־û���ʹ��log���S�҂����οɿ��ظ���master�Ġ�B(t��i)������Ó�(d��n)�Į�(d��ng)master crash�ĕr��IJ�һ�������Master���]�����ñ���chunk��λ����Ϣ�����������master���ӻ���ij��chunkserver���뼯Ⱥ�r�����������ÿ��chunkserverԃ������chunks��Ϣ��</P>
<P style="TEXT-INDENT: 2em"> 2.6.1 ��(n��i)�攵(sh��)��(j��)�Y(ji��)��(g��u)</P>
<P style="TEXT-INDENT: 2em">����Ԫ��(sh��)��(j��)�惦�ڃ�(n��i)�������master�IJ����Ǻܿ�����������ˌ���master���f�������Ժ�����Ч�،��ں��_������B(t��i)�M�������Ԓ����������@�������ԵĒ������Á팍�F(xi��n)chunk�������գ�chunkserver���F(xi��n)ʧ���r�M�е��؏�(f��)������Լ�����ƽ��ؓ�d�ʹűP���g��chunkserver�g��chunk �w�ơ�4.3 4.4���Mһ��ӑՓ�@Щ��������</P>
<P style="TEXT-INDENT: 2em"> �@��ȫ��(n��i)����Դ���һ�����ڵ����ƾ���chunk�Ĕ�(sh��)Ŀ�����������ϵ�y(t��ng)������ȡ�Q��master�ж��ٿ��Ã�(n��i)������������H���@����һ���܇��ص������������Master��ÿ��64MB��chunk�S�o����64byte�Ĕ�(sh��)��(j��)�����ֵ�chunk�ǝM�����������ֵ��ļ���������chunk��ֻ�����һ��chunk������δ����������Ƶ������ÿ���ļ����ֿ��g��(sh��)��(j��)ͨ����Ҫ����64byte����ļ����Q�惦�r��ʹ��ǰ�Y���s�㷨�M�Љ��s����</P>
<P style="TEXT-INDENT: 2em"> �����Ҫ֧�ָ�����ļ�ϵ�y(t��ng)������ֻ��Ҫ��master�����Ӄ�(n��i)����������@�c�_�N�cͨ�^��Ԫ��(sh��)��(j��)�惦����(n��i)�����õ������ԣ��ɿ���������ܺ��`���ԣ����Ǻ�С��һ�P���M�����</P>
<P style="TEXT-INDENT: 2em"> 2.6.2 chunk location</P>
<P style="TEXT-INDENT: 2em"> Master���]���ṩһ�������ԵĴ惦���挦��һ���o����chunk������Щchunkserver���������ĸ������������ֻ���چ��ӕr����������ε؏�chunkserver������@Щ��Ϣ���^����Master�܉��C���Լ��Ǹ����^��������������������chunk�ķ��ã��Լ�ͨ�^�����Ե�������Ϣ���O(ji��n)��chunkserver�������</P>
<P style="TEXT-INDENT: 2em"> ��������҂��Lԇ��chunkλ����Ϣ���ñ�����master�����������҂��l(f��)�F(xi��n)�چ��ӕrȥchunkserverՈ���@Щ��(sh��)��(j��)����������@�ӱ����ˮ�(d��ng)chunkserver�ڼ�������x�_��Ⱥ������������������ʧ����������؆��ȴ��r��Ҫ��master�cchunkserver�g��ͬ�������һ����(sh��)���_�C���ļ�Ⱥ�У��@�ӵ��¼�̫��(j��ng)��������</P>
<P style="TEXT-INDENT: 2em"> �����@���O(sh��)Ӌ�Q������һ����ʽ��chunkserver�����Լ���߀�Ǜ]��ij��chunk������K�İl(f��)�ԙ�(qu��n)�����master�ϾS�oһ���@Щ��Ϣһ����ҕ�D�Ǜ]�����x�ģ����l(f��)����chunkserver�ϵ��e�`����ʹ��һЩchunkͻȻ�g��Ҋ��(����Ӳ�P���ܕ��ĵ����߲�����)������һ���������܌�chunkserver��������</P>
<P style="TEXT-INDENT: 2em"> 2.6.3������־</P>
<P style="TEXT-INDENT: 2em">������־�������P(gu��n)�IԪ��(sh��)��(j��)��׃�Ěvʷӛ��������GFS�ĺ��ġ������H��Ԫ��(sh��)��(j��)��Ψһһ����ӛ䛣�������Ҳ���x����Щ���l(f��)������߉�ϵĕr�g����������ļ���chunk�İ汾����Ψһ���������������(chu��ng)���r��߉�r�g����R������</P>
<P style="TEXT-INDENT: 2em"> ��˲�����־�Ǻ��P(gu��n)�I����������҂���횿ɿ��ر�����������κ�Ԫ��(sh��)��(j��)׃�����־û�֮ǰ����(y��ng)��(d��ng)���͑��˿�������t��������҂����Gʧ�����ļ�ϵ�y(t��ng)��������Ŀ͑��˲�����ʹchunckserver�Լ����������������������҂���������ڶ����h�̙C���������������һ���͑��˲���ֻ�Ю�(d��ng)ԓ��������(y��ng)����־ӛ䛱�ˢ�µ����غ��h�̵ĴűP�ϕr�ŕ��l(f��)��푑�(y��ng)�����Master���ׂ�������־����һ�Kˢ�������Ķ�����ˢ�º͏�(f��)�ƌ�������ϵ�y(t��ng)�����ʵ�Ӱ�������</P>
<P style="TEXT-INDENT: 2em"> Masterͨ�^����(zh��)�в�����־���֏�(f��)�����ļ�ϵ�y(t��ng)����������С�����ӕr�g������҂���회���־�DZ����ں�С��Ҏ(gu��)ģ������(d��ng)��־���L���^һ���Ĵ�С������Master�o���Ġ�B(t��i)�O(sh��)�Ùz���c������������ͨ�^�ı��شűP���d���µęz���c�M�л֏�(f��)������Ȼ������(zh��)����Щ��ԓ�z���c֮�����־ӛ䛡��z���c������һ�����s���B��ĽY(ji��)��(g��u)��������Ҫ�~��Ľ����Ϳ���ֱ��ӳ�䵽��(n��i)���������ֿ��g��������@�������˻֏�(f��)���ٶȺͿ����ԡ�</P>
<P style="TEXT-INDENT: 2em"> ��齨��һ���z���c�����MһЩ�r�g��master�ă�(n��i)����B(t��i)�ĽY(ji��)��(g��u)�O(sh��)Ӌʹ��һ���µęz���c���Բ���Ҫ�ӕr��Щ���ܵ���׃���Ϳ��Ա���(chu��ng)�����Master������һ���µľ����ГQ��һ���µ���־�ļ�Ȼ��(chu��ng)���µęz���c���@���µęz���c�������ГQ֮ǰ������׃������������һ�������װ��f�ļ��ļ�Ⱥ�����Ҫ��犾Ϳ�����ɡ��Y(ji��)������������������ر��غ��h�̵ĴűP��</P>
<P style="TEXT-INDENT: 2em"> �֏�(f��)ֻ��Ҫ������ȫ�ęz���c�ͺ������־�ļ��������ϵęz���c����־�ļ��������ɵĄh��������(d��ng)Ȼ�҂���������һЩ�푪(y��ng)��ijЩͻ�l(f��)��r��������ڄ�(chu��ng)���z���c�ĕr��l(f��)����ʧ������Ӱ�ϵ�y(t��ng)�����_������������֏�(f��)���a���z�y�����^����ȫ�ęz���c�����</P>
<P style="TEXT-INDENT: 2em"> 2.7һ����ģ��</P>
<P style="TEXT-INDENT: 2em"> GFSʹ�õ�һ�����ɵ�һ����ģ�Ͳ����ܺõ�֧�����҂��ĸ߶ȷֲ�ʽ�đ�(y��ng)�ã����Ҍ��F(xi��n)����Ҳ�������κ���Ч���������҂��F(xi��n)��ӑՓGFS���ṩ�ı��C�Լ���������(y��ng)�ó������ζ��ʲô�����҂�Ҳ���v��GFS��ξS�o�@Щ���C������Ǖ������w�ļ���(ji��)��������Փ�����v������</P>
<P style="TEXT-INDENT: 2em"> 2.7.1 GFS�ṩ�ı��C</P>
<P style="TEXT-INDENT: 2em">�ļ����ֿ��g�ĸ�׃(�����ļ���(chu��ng)��)��ԭ���Ե������������ֻ��master�M��̎�������ֿ��g�i�����Cԭ���Ժ����_��(4.1��(ji��))���Master�IJ�����־���x���@Щ������ȫ���Ե�����</P>
<P style="TEXT-INDENT: 2em"> ��(d��ng)��(sh��)��(j��)׃���������ļ��^(q��)��Ġ�B(t��i)ȡ�Q��׃����������׃���Ƿ�ɹ��Լ��Ƿ��Dz��l(f��)�M�еġ���1�nj��Y(ji��)����һ����������</P>
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515229WIDR.png" target=_blank><IMG src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515229WIDR.png" border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">������еĿ͑��˟oՓ���Ă������xȡ��(sh��)��(j��)���ǿ�����ͬ�Ĕ�(sh��)��(j��)�����ô�҂����f�ļ��^(q��)����һ�µġ�����ļ���(sh��)��(j��)׃������һ�µ����ͬ�r�͑��˿��Կ��������е�׃������ô�҂����f�ļ��^(q��)���Ѷ��x�������(d��ng)һ��׃���ɹ����қ]���ܵ��������l(f��)���ߵ�Ӱ����������ô��Ӱ푵ą^(q��)����Ƕ��x���õ�(�϶���һ���Ե�)�����еĿ͑��ˌ�������������׃�������l(f��)�ijɹ���׃��������ʹ�^(q��)���M��δ���x�Ġ�B(t��i)����߀��һ�µģ����еĿ͑��˿��Կ���һ�µĔ�(sh��)��(j��)���������������ܟo���������е�׃��(���׃����ᘌ���ͬ�Ĕ�(sh��)��(j��)���@���е�׃���͕����µ�׃�������w���@���Ñ��͟o���������ȵ�׃�����������ͬ�r�l(f��)���ڿ�chunk�IJ���������ֳɃɂ�����������@���@��������һ���ֿ��ܕ��������������w��������һ���քt��������������3.1��(ji��)ĩβ����)�����ͨ�����������Ƕ���׃���M�Ϻ�ĽY(ji��)������һ��ʧ����׃����ʹ�^(q��)���M���һ�µĠ�B(t��i)(���Ҳ��δ���x�Ġ�B(t��i))����ͬ�Ŀ͑����ڲ�ͬ���L���п��ܿ�����ͬ�Ĕ�(sh��)��(j��)������҂������������҂��đ�(y��ng)�ó�����΅^(q��)�ֶ��x���õą^(q��)���δ���x�ą^(q��)��(y��ng)�ó�����Ҫ�Mһ���^(q��)��δ���x�^(q��)��ĸ��N��ͬ�����������</P>
<P style="TEXT-INDENT: 2em"> ��(sh��)��(j��)׃�������nj�����ӛ�append����������ʹ��(sh��)��(j��)�ڑ�(y��ng)�ó���ָ����ƫ��λ�Ì���������ӛ�append������ʹ��(sh��)��(j��)ԭ���Ե�append������Dz��l(f��)�Ե�Ԓ�t���ٕ���appendһ���������ƫ��λ������GFS�Q����(Ȼ����ͨ��������������ڿ͑����댑����ǂ��ļ���β��)�������ƫ��λ�Õ������ؽo�͑�������ͬ�r��ӛ�����@�lӛ䛵��ǂ����x���õ��ļ��^(q��)�����ʼλ������������GFS���ܕ�������֮�g����һЩpadding����ӛ䛵ĸ�����������ռ��(j��)��Щ���J���Dz�һ�µą^(q��)�����ͨ���������Ñ���(sh��)��(j��)С�Ķࡣ</P>
<P style="TEXT-INDENT: 2em"> ��һϵ�гɹ���׃��֮�������׃�����ļ��^(q��)���C���Ѷ��x������ͬ�r���������һ��׃���Ĕ�(sh��)��(j��)���������GFSͨ�^�ɷN��ʽ�팍�F(xi��n)�@�N�Y(ji��)��a.���@Щ׃������ͬ�IJ������(y��ng)����ԓchunk�����еĸ���������b.ʹ��chunk�İ汾̖��z�y��Щ���f�ĸ�����������������chunkserver����˶��Gʧ��һЩ׃�������f�ĸ������h���������c׃�����߷��ؽo��Щ��masterԃ��chunkλ�õ�client�����������(y��u)�ȅ��c�������ա�</P>
<P style="TEXT-INDENT: 2em"> ���͑��˕�����chunk��λ���������Ϣ����֮ǰ�������ܕ��x����f�ĸ������r�g�����ɾ���ֵ�ij��r�r�g�Լ��ļ�����һ�δ��_������������ļ��Ĵ��_�����������ԓ�ļ����P(gu��n)��chunk��Ϣ�������������������҂��Ĵֲ�������ӛ䛵�append�������һ����f����ͨ��������һ���^��Y(ji��)����chunk�������^�r�Ĕ�(sh��)��(j��)��������(d��ng)�xȡ����ԇ���cmaster(li��n)ϵ�r����������������õ���(d��ng)ǰ��chunkλ�á�</P>
<P style="TEXT-INDENT: 2em"> �ɹ���׃���ܾ�֮������M��ʧ�����п����ƉĻ�����Ⱦ��(sh��)��(j��)��GFSͨ�^�����Ե���master������chunkserver�g�����ҵ���Щʧ����chunkserver������ͬ�rͨ�^У��(5.2��(ji��))��z�y��(sh��)��(j��)����Ⱦ��һ���l(f��)�F(xi��n)���}��������M����������_�ĸ����֏�(f��)(4.3��(ji��))�����ֻ��һ���K�����и�����GFS��������(y��ng)֮ǰ��ȫ���Gʧ�������@���K�ŕ��������D(zhu��n)�āGʧ����ͨ��GFS�ķ���(y��ng)���ڎ�犃�(n��i)��������ʹ���@�N��r����������K�����ã������DZ���Ⱦ����(y��ng)�ó�����յ��������e�`��Ϣ�����DZ���Ⱦ�Ĕ�(sh��)��(j��)�������</P>
<P style="TEXT-INDENT: 2em">2.7.2 ���ڑ�(y��ng)�ó����Ӱ�</P>
<P style="TEXT-INDENT: 2em">GFS��(y��ng)�ó������ͨ�^ʹ�ú��εļ��g(sh��)���m��(y��ng)�@�N���ɵ�һ����ģ������@Щ���g(sh��)�ѽ�(j��ng)������Ŀ������Ҫ����ه�cappend���������Ǹ��w���z���c���������r������C���Լ����Rӛ������</P>
<P style="TEXT-INDENT: 2em"> ���H������҂����еđ�(y��ng)�ó�����ͨ�^append�����Ǹ��w����׃�ļ������һ�����͑�(y��ng)���У�һ���������ߕ����^��β����һ���ļ����������(d��ng)�������Д�(sh��)��(j��)�����ԄӵČ��ļ���������һ�������Ե����Q�����������ͨ�^�����Եęz���c�z���ѽ�(j��ng)�ж��ٔ�(sh��)��(j��)���ɹ������ˡ��z���c���ܕ��O(sh��)�Ñ�(y��ng)�ü���У�������xȡ�߃H��C��̎�����һ���z���c֮ǰ���ļ��^(q��)�������@Щ�^(q��)��̎���Ѷ��x�Ġ�B(t��i)�������oՓʲô�ӵIJ��l(f��)��һ����Ҫ���@�������������ĺܺ�����Append�������S�C�����ڑ�(y��ng)�ó����ʧ��̎����������Ҫ������Ч���Џ�������z���c���S�������������Ե��؆�(����Ҫ�����^��)��������S�xȡ�߿���̎����Щ�ѽ�(j��ng)�ɹ�����Ĕ�(sh��)��(j��)�������mȻ�ڑ�(y��ng)ԓ����Ŀ�����Ȼ�Dz���ȫ������</P>
<P style="TEXT-INDENT: 2em"> ��һ�N���͵đ�(y��ng)���������ܶ�����ͬ�r��һ���ļ�append���˚w���ļ�����������һ�����a(ch��n)�����M������������ӛ䛵�append��append-at-least-once�Z�x���C��ÿ�����ߵ�ݔ�����xȡ���@��̎��żȻ��padding���؏�(f��)��(sh��)��(j��)��������ߞ�ÿ�lӛ䛜ʂ�һЩ�~����Ϣ����У��������@�����ĺϷ��ԾͿ�����C��������������؏�(f��)�Ĕ�(sh��)��(j��)(�������������|�l(f��)�ǃ�Ȳ���)�������ͨ�^��ӛ���ʹ��Ψһ���R�����^�V�������ܶ��r����Ҫ�@Щ���R����������(y��ng)�đ�(y��ng)�ó���?q��)��w���������W(w��ng)��ęn����@Щ����recordݔ��ݔ���Ĺ��ܺ���(sh��)���Ԏ����ʽ���҂��đ�(y��ng)�ó�������������ͬ�r��(y��ng)����gongle�������ļ��ӿڌ��F(xi��n)��������������ͬϵ�е�ӛ���������һЩ��Ҋ���؏�(f��)����������ֱ�ӱ��ְl(f��)�oӛ��xȡ�����</P>
<P style="TEXT-INDENT: 2em"> �����ϵ������������������һ�������ļٶ�����(sh��)��(j��)����record��ʽ�惦�������������ͨ���@Щrecord���ǿ����؏�(f��)������������һ���W(w��ng)��ęn�҂������؏�(f��)�棬�@���ڔ�(sh��)�ك|�ľW(w��ng)��ęn���f������惦�ٔ�(sh��)����ĺ�������Ҳ�����f�@Щ��(sh��)��(j��)ͨ�����ı�����������Ƕ��M�����������҂��ſ�����append���ߌ��r��ӛ䛵ĸ��������w��һ�µą^(q��)��������������ṩ��append��append-at-least-once�Z�x����������append����Ҳ�ǿ��Ե����������҂�Ҫ���CΨһ�����������ڑ�(y��ng)�Ì�����߉�������</P>
<P style="TEXT-INDENT: 2em">3.ϵ�y(t��ng)����</P>
<P style="TEXT-INDENT: 2em">�҂����ԱM����С��master�����в����еą��c�ȁ��O(sh��)Ӌϵ�y(t��ng)������������@���������������҂��F(xi��n)��������client���master�Լ�chunkserver��ν����팍�F(xi��n)��(sh��)��(j��)׃����ӛ�append�Լ����յ����� </P>
<P style="TEXT-INDENT: 2em">3.1��s��׃�����</P>
<P style="TEXT-INDENT: 2em">һ��׃����ָһ����׃chunk�ă�(n��i)�ݻ���Ԫ��Ϣ�IJ����������猑��������append�������ÿ��׃������Ҫ�����еĸ����ψ�(zh��)�������҂�ʹ����s�����ֶ��������g׃������һ�����������Master�ڙ�(qu��n)�o���е�һ������һ��ԓchunk����s��������҂�����������������������@����������ᘌ�ԓchunk������׃�����x��һ����(zh��)�����������Ȼ�����еĸ�������(j��)�@������(zh��)��׃������������ȫ�ֵ�׃�������������master�x�����s�ڙ�(qu��n)�����_����(�����ж���chunk��Ҫ�M����)�������ͬһ����s��(n��i)��׃�����t�����ǂ������������x������� </P>
<P style="TEXT-INDENT: 2em">��s�C���Ǟ�����С��master�Ĺ����_�N���O(sh��)Ӌ������һ����s��һ����ʼ����60s�ij��r�r�g�O(sh��)�������Ȼ��ֻҪ�@��chunk����׃�����ǂ��������Ϳ�����masterՈ�����L��s�������@ЩՈ����ڙ�(qu��n)ͨ�����cmaster��chunkserver�g��������Ϣһ��l(f��)�͵ġ��Еr��master����������s�^��ǰ���N��(���������master������ʹ��һ���������������ļ���׃���oЧ)��������ʹmaster�o���c�������M��ͨ����������Ҳ�������f����s�^�ں�ȫ�Č���s�ڙ�(qu��n)�o��һ���µĸ����� </P>
<P style="TEXT-INDENT: 2em">��D2����҂��������µĔ�(sh��)�֘��R�IJ��E����ʾһ���������Ŀ������̡�</P>
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_12955153451MDl.png" target=_blank><IMG style="WIDTH: 413px; HEIGHT: 370px" height=370 src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_12955153451MDl.png" width=420 border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em">1.client��masterԃ���ǂ�chunkserver�@ȡ�ˮ�(d��ng)ǰchunk����s�Լ������������ڵ�λ���������]���˵õ���s��master����s�ڙ�(qu��n)�o���x���һ�����������</P>
<P style="TEXT-INDENT: 2em">2.master����ԓ�������Ę��R���Լ�����������λ�������Client��δ����׃�������@����(sh��)��(j��)�������ֻ�Ю�(d��ng)�������]��푑�(y��ng)������s���ڕr������Ҫ�cmaster(li��n)ϵ���</P>
<P style="TEXT-INDENT: 2em">3.client����(sh��)��(j��)���ͽo���еĸ���������client���������������M�����͡�ÿ��chunkserver������(sh��)��(j��)����ڃ�(n��i)����LRU buffer���������ֱ����(sh��)��(j��)��ʹ�û����^�������ͨ�^���������c��(sh��)��(j��)�����x�����҂�����ͨ�^�����F�Ĕ�(sh��)��(j��)�����ھW(w��ng)�j(lu��)�ؓ��M���{(di��o)�ȁ��������������������ÿ��]�Ă�chunkserver����������3.2��(ji��)�������ӑՓ���@�c�����</P>
<P style="TEXT-INDENT: 2em">4.һ�����еĸ������ܵ��˔�(sh��)��(j��)�������client�l(f��)��һ����Ո��o�������������@��Ո����R����ǰ���ͽo���и����Ĕ�(sh��)��(j��)�����������o���յ�������׃��(���܁��Զ���client)����һ���B�m(x��)������̖���M�б���Ĵ��л����������@Щ׃������(j��)����̖��(y��ng)���ڱ��ظ��������</P>
<P style="TEXT-INDENT: 2em">5.����������Ո��l(f��)�ͽo���еĴθ�����ÿ���θ������c��������ͬ�Ĵ��л����(y��ng)���@Щ׃���������</P>
<P style="TEXT-INDENT: 2em">6.���еĴθ�����ɲ����������������ؑ�(y��ng)��</P>
<P style="TEXT-INDENT: 2em">7.��������client���ؑ�(y��ng)�������κθ����������e�`�������ؽoclient������F(xi��n)�e�`�r��ԓ�����������ѽ�(j��ng)���������Լ�һ���ִθ����ψ�(zh��)�гɹ�����(���������ʧ����������ô����������һ������̖���Ұl(f��)�ͽo������)��������͑���Ո�����J����ʧ���ģ����ĵą^(q��)��?q��)���̎�ڷ�һ� �B(t��i)������҂��Ŀ͑��˴��a��ͨ�^��ԇ׃����̎���@�ӵ��e�`������������3-7���E�g�M��һЩ�Lԇ���������^��ԇ�@��������������</P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">�����(y��ng)�ó����һ���������ܴ���߿�Խ��chunk��߅�磬GFS client���a�������D(zhu��n)�����������������������������ѭ����Ŀ������̣����ǿ��ܕ�����������client�IJ���������߸��w������˹������ļ��^(q��)����ܕ��������Բ�ͬclient��Ƭ������mȻ�@Щ������һ�µģ�������еIJ�����������ͬ����������и����ψ�(zh��)�гɹ������������ļ��^(q��)���̎��һ�Nһ�µ���δ���x�Ġ�B(t��i)�����������2.7��(ji��)�������ǘӡ�</P>
<P style="TEXT-INDENT: 2em"> 3.2��(sh��)��(j��)��</P>
<P style="TEXT-INDENT: 2em">���˸���Ч��ʹ�þW(w��ng)�j(lu��)�҂�����(sh��)��(j��)���Ϳ��������x����������������client���_�����������Ȼ���_���������дθ����������(sh��)��(j��)�t�Ǿ��Ե�ͨ�^һ���м��x���chunkserver�����ˮ���ǘ������^ȥ��������҂���Ŀ���dz������ÿ���C���ľW(w��ng)�j(lu��)�����������W(w��ng)�j(lu��)ƿ�i���ӕr�·������С����(sh��)��(j��)���͵��ӕr�������</P>
<P style="TEXT-INDENT: 2em"> ���˳������ÿ���C���ľW(w��ng)�j(lu��)���������(sh��)��(j��)ͨ�^chunkserver朾��Ե������^ȥ���������������ؓ��M�зֲ�������͡����ÿ���C���Ď�������ȫ���Á��l(f��)�͔�(sh��)��(j��)�����Ǟ�����������M���з��������</P>
<P style="TEXT-INDENT: 2em"> ���˱M���ܵı���W(w��ng)�j(lu��)ƿ�i���ӕr�·��ÿ���C����W(w��ng)�j(lu��)��߀�]���յ�ԓ��(sh��)��(j��)��������ǂ��C�����͔�(sh��)��(j��)������O(sh��)client����(sh��)��(j��)���ͽoS1- S4���������Ȍ���(sh��)��(j��)���ͽo�����chunkserver���O(sh��)��S1������S1���ͽo����ģ����O(sh��)S2�����S2���ͽoS3�����S4���x��������ǂ����҂��W(w��ng)�j(lu��)�ؓ������������ھ��x����ͨ�^IP��ַ��Ӌ������</P>
<P style="TEXT-INDENT: 2em"> ��������С���ӕr��������҂�ͨ�^��TCP��(sh��)��(j��)��ݔ�M����ˮ���������һ��һ��chunkserver�յ���(sh��)��(j��)����������_ʼ�������°l(f��)�͔�(sh��)��(j��)���������ˮ�����҂����f������������������҂�ʹ����һ��ȫ�p���·�Ľ��Q�W(w��ng)�j(lu��)��������l(f��)�͔�(sh��)��(j��)���������͔�(sh��)��(j��)�������ʡ�����]�оW(w��ng)�j(lu��)������������R��������ݔB�ֹ�(ji��)�Ĕ�(sh��)��(j��)����ĕr�g���M��B/T+RL,T�����W(w��ng)�j(lu��)�����ʣ�L�ǙC���g�ľW(w��ng)�j(lu��)�ӕr������҂��ľW(w��ng)�j(lu��)�B����100Mbps(T),L�h�h����1ms����������1MB�Ĕ�(sh��)��(j��)������r����Ҫ80ms�Ϳ���������</P>
<P style="TEXT-INDENT: 2em">3.3ԭ���Ե�ӛ�append</P>
<P style="TEXT-INDENT: 2em">GFS�ṩһ��ԭ���Ե�append��������record append(ע���@�c���y(t��ng)��append����Ҳ�Dz�ͬ��)������ڂ��y(t��ng)�Č������������Ñ�ָ����(sh��)��(j��)��Ҫ���ı���λ���������������ͬ�^(q��)��IJ��Ќ������Dz��ɴ��еģ�ԓ�^(q��)���ĩβ���ܰ������Զ���client�Ĕ�(sh��)��(j��)Ƭ������������һ��record append�����У�clientΨһ��Ҫ�f����ֻ�Д�(sh��)��(j��)�����GFS����������ԭ���Ե�append���ļ���һ������append��λ������GFS�x�����������ͬ�r�����@��λ�÷��ؽoclient���@�������unix�ļ����_ģʽ�е�O_APPEND���������(d��ng)�������߲��l(f��)�����r�����a(ch��n)�������l�����</P>
<P style="TEXT-INDENT: 2em"> Record append���҂��ķֲ�ʽ��(y��ng)���б�������ʹ�á��ܶ��ڲ�ͬ�C����client���l(f��)����ͬһ���ļ�append���������ʹ�Â��y(t��ng)�Č���������client����Ҫ�M�Џ�(f��)�s���ְ��F��ͬ�����������������ͨ�^һ���ֲ�ʽ�i�����������҂��Ĺ���ؓ�d���������@�ӵ��ļ�ͨ������һ�������a(ch��n)��/�����M����л����Á�������Զ�����ͬclient�Ěw���Y(ji��)����</P>
<P style="TEXT-INDENT: 2em"> Record append��һ�N��͵�׃���������������һ�c���������ϵ��~���߉����Ȼ��ѭ3.1��(ji��)�Ŀ�������Client�����еĔ�(sh��)��(j��)���ͽo���и����������������������l(f��)��Ո���������z�錢ԓӛ�append��ԓchunk�Ƿ����(d��o)��ԓchunk���^�������ֵ(64MB)����������^��������͌�ԓchunk��䵽���ֵ�����V�θ�����ͬ�ӵĹ���������Ȼ����V�͑���ԓ������(y��ng)ԓ����һ��trunk����ԇ��(append��Record��С��Ҫ���������trunk��С���ķ�֮һ�ԃ�(n��i)�������@�ӿ��Ա��C�����r�µ���Ƭ���Ա�����һ�����Խ��ܵ�ˮƽ�� )���������ӛ䛿��ԛ]�г��^���ߴ��������Ͱ�����ͨ��r̎��������������(sh��)��(j��)append�����ĸ������������V�θ�������(sh��)��(j��)������ͬ��ƫ��λ��������������client���سɹ���(y��ng)��</P>
<P style="TEXT-INDENT: 2em"> ���record append���κ�һ��������ʧ����client�͕���ԇ�@�����������@�������ͬchunk�Ķ��������Ϳ��ܰ�����ͬ�Ĕ�(sh��)��(j��)��������@Щ��(sh��)��(j��)���ܰ�������ͬӛ䛵��������߲��ֵ��؏�(f��)ֵ��GFS�������C���еĸ�����λ���e�ϵ�һ���ԣ���ֻ���C��(sh��)��(j��)����һ��ԭ�ӆ�Ԫ���ٌ���һ�Ρ��@�������������µĺ����^���ƌ�(d��o)�����������(d��ng)�������ɹ��r��������(sh��)��(j��)�϶������뵽ij��trunk�����и�������ͬƫ��λ����������˺��������еĸ��������_����ӛ�β���Ĵ�С���������δ����ӛ䛌����������ڸ��ߵı���λ�ã���������һ����ͬ��chunk������ʹ��һ������׃���������������҂���һ���Ա��C�������record append�����ɹ����µĔ�(sh��)��(j��)�^(q��)�����Ѷ��x��(�϶���һ�µ�)��Ȼ���������g�Ĕ�(sh��)��(j��)�t�Dz�һ�µ�(���Ҳ��δ���x��)������҂��đ�(y��ng)�ó������̎���@�ӵIJ�һ�
^(q��)�������҂���2.7.2��ӑՓ���ǘ��������</P>
<P style="TEXT-INDENT: 2em"> 3.4����</P>
<P style="TEXT-INDENT: 2em">���ղ������Էdz�����ٵı����ļ�����Ŀ䛘��һ����ؐ������ͬ�r������С���������ڈ�(zh��)�е�׃���������Дࡣ�Ñ���(j��ng)�������턓(chu��ng)����(sh��)��(j��)���ķ�֧��ؐ��������Լ���ؐ�Ŀ�ؐ�����������������Á턓(chu��ng)���z���c���Ԍ�Ҫ�ύ�Ŀ�ؐ���؝L������Ġ�B(t��i)���</P>
<P style="TEXT-INDENT: 2em"> ��AFS���҂�ʹ�ؘʵČ��r��ؐ���g(sh��)�팍�F(xi��n)����������(d��ng)master�յ�һ������Ո��r�����������ȳ��N��Ҫ�M�п��յ���Щ�ļ�����(y��ng)��chunk�������Ѱl(f��)������s���@��ʹ�Ì����@Щchunk�ĺ��m(x��)��������Ҫ�cmaster�������õ���s�����������@�����Ƚomasterһ���C����(chu��ng)��ԓchunk���µĿ�ؐ����</P>
<P style="TEXT-INDENT: 2em"> ��(d��ng)�@Щ��s�����N�����^�ں������master���@Щ��������־��ʽ����űP����Ȼ���(f��)��ԓ�ļ�����Ŀ䛘��Ԫ��(sh��)��(j��)�������Ȼ���@Щ��־ӛ䛑�(y��ng)�õ���(n��i)���еď�(f��)�ƺ�Ġ�B(t��i)�������(chu��ng)���Ŀ����ļ��cԴ�ļ�һ��ָ����ͬ��chunk�������</P>
<P style="TEXT-INDENT: 2em"> ��(d��ng)client�ڿ�����Ч���һ�Ό�һ��chunk C�M�Ќ���r������������l(f��)��Ո��omaster�ҵ���(d��ng)ǰ��s�������������Masterע�����chunk C������Ӌ��(sh��)����1���������t�؏�(f��)�͑��˵�Ո�������x��һ���µ�chunk handle C`�����Ȼ��ÿ������C����Щchunkserver��(chu��ng)��һ���µĽ���C`��chunk�������ͨ�^����ͬ��chunkserver�ϸ���(j��)ԭʼ��chunk��(chu��ng)����chunk�����ͱ��C�˔�(sh��)��(j��)��ؐ�DZ��ص��������������ͨ�^�W(w��ng)�j(lu��)(�҂���Ӳ�P��100Mbps�W(w��ng)�j(lu��)��������)��������@�������������κ�chunk��Ո��̎�����]��ʲô��ͬ��master���²�chunk C`�ĸ����е�һ���ڙ�(qu��n)��s�������Ȼ�ؽoclient�������@�����Ϳ��������Č��@��chunk�ˣ�client����Ҫ֪��ԓchunk���H���Ǐ�һ���F(xi��n)�е�chunk��(chu��ng)�������������</P>
<P style="TEXT-INDENT: 2em"> 4.master����</P>
<P style="TEXT-INDENT: 2em">Master��(zh��)�����е����ֿ��g���������������������߀��������ϵ�y(t��ng)��chunk��ݣ��Q����η����������(chu��ng)���µ�chunk������(y��ng)�ĸ������f(xi��)�{(di��o)����ϵ�y(t��ng)�Ļ�ӱ��Cchunk����������ݵ����������chunkserver�g�M��ؓ�dƽ������������՛]��ʹ�õĴ惦���g����҂��F(xi��n)��ӑՓ�@Щ���}��</P>
<P style="TEXT-INDENT: 2em"> 4.1���ֿ��g�������i</P>
<P style="TEXT-INDENT: 2em">�ܶ�master��������Ҫ���M���L�r�g�����������һ�����ղ���Ҫ���Nԓ������������chunk��������s��������҂������뵢�`�����\���е�master�������������҂����S��������ͬ�r�ǻ�ӵģ�ͨ�^�����ֿ��g�^(q��)��ʹ���i�����C���_�Ĵ��л������</P>
<P style="TEXT-INDENT: 2em"> ������y(t��ng)���ļ�ϵ�y(t��ng)����GFS��Ŀ䛲��]��һ�N��(sh��)��(j��)�Y(ji��)��(g��u)�Á��г�ԓĿ��������ļ�������Ҳ��֧���ļ�����Ŀ䛄e��(��unix��Ӳ朽ӻ���ܛ�B���ǘ�)������GFS��߉��ͨ�^һ��·��ȫ�Q��Ԫ��(sh��)��(j��)ӳ��IJ��ұ����ʾ�������ֿ��g��ͨ�^����ǰ�Y���s���@����������Ч���ڃ�(n��i)���б�ʾ��������ֿ��g���е�ÿ����(ji��)�c(Ҫô���ļ��Ľ^��·�����QҪô��Ŀ䛵�)����һ�����P(gu��n)(li��n)���x���i���</P>
<P style="TEXT-INDENT: 2em"> ÿ��master���������\��ǰ���������Ҫ�@��һ���i�ļ��ϡ���������������/d1/d2��/dn/leaf��������ô����Ҫ�@��/d1,/d1/d2����/d1/d2��/dn�@ЩĿ䛵��x�i��Ȼ����ܵõ�·��/d1/d2��/dn/leaf���x�i���ߌ��i��Leaf�����ǂ��ļ�����Ŀ������@ȡ�Q�ھ��w�IJ���������</P>
<P style="TEXT-INDENT: 2em"> �҂��F(xi��n)�ڽ��һ��������(d��ng)��/home/user��(chu��ng)������/save/user�r���i�C����η�ֹ�ļ�/home/user/foo����(chu��ng)����������ղ�����Ҫ�@����/home /save�ϵ��x�i��������Լ�/home/user��/save/user�ϵČ��i��������ļ���(chu��ng)����Ҫ�@����/home��/home/user�ϵ��x�i������Լ���/home/user/foo�ϵČ��i���@�ɂ��������������_�Ĵ��л��������������ԇ�D�@ȡ��/home/user�ϵ����_ͻ���i���ļ���(chu��ng)��������Ҫ��Ŀ䛵Č��i�����錍�H���@�ﲢ�]�С�Ŀ䛡������f�������inode�Ĕ�(sh��)��(j��)�Y(ji��)��(g��u)��������Ҫ��ֹ����������x�i�ѽ�(j��ng)����Á���ֹ��Ŀ䛱��h�����</P>
<P style="TEXT-INDENT: 2em">�@�N�iģʽ��һ����̎���������S����ͬĿ䛵IJ��l(f��)׃�������������������ļ��Ą�(chu��ng)����������ͬĿ��²��l(f��)��(chu��ng)����ÿ���@��ԓĿ䛵�һ���x�i���Լ��ļ���һ�����i����Ŀ����Q�ϵ��x�i�����Է�ֹĿ䛱��h����������������߿��ա��ļ����Q�ϵČ��i�������C�؏�(f��)��(chu��ng)����ͬ���Q���ļ��IJ���ֻ������(zh��)��һ������</P>
<P style="TEXT-INDENT: 2em">������ֿ��g�кܶ(ji��)�c���������x���i����ֻ������Ҫ�r�ŕ��������������һ������ʹ���þ̈́h�������˱������i������i�ǰ���һ��һ�µ�ȫ���P(gu��n)ϵ�M�Ы@ȡ�ģ����ȸ���(j��)��̎�����ֿ��g��ļ��e���������ͬ���e�Ąt����(j��)�ֵ���</P>
<P style="TEXT-INDENT: 2em"> 4.2 ��ݷ���</P>
<P style="TEXT-INDENT: 2em">GFS�ڶ����Ӵ��϶����и߶ȵķֲ�ʽ���������Д�(sh��)�ق�ɢ���ڶ����C���е�chunkserver����@Щchunkserver�ֿ��Ա����Բ�ͬ������ͬ�C���ϵ�client�L����̎�ڲ�ͬ�C��ęC���g��ͨ�ſ�����Ҫ���^һ�����߸���ľW(w��ng)�j(lu��)���Q�C�������������M��һ���C��Ď������ܕ�С�ڙC���(n��i)���ЙC���Ď������͡��༉�ķֲ�ʽ�����˔�(sh��)��(j��)�ֲ�ʽ�r�ĔUչ�������ɿ��ԺͿ����Է��������(zh��n)���</P>
<P style="TEXT-INDENT: 2em"> Chunk�Ă�ݷ��ò��Է���(w��)�ڃɂ�Ŀ�ģ����(sh��)��(j��)�ɿ��ԺͿ����ԣ���С���W(w��ng)�j(lu��)������ʹ�á������_���@�ɂ�Ŀ������H�H����ݷ��ڲ�ͬ�ęC���Dz���ģ��@ֻ�ܑ�(y��ng)���C������Ӳ�Pʧ�������Լ��������ÿ�_�C���Ď����������҂�����ڙC���g��ł�������@���܉��C��(d��ng)һ���C�������p�Ļ����x��(����W(w��ng)�j(lu��)���Q�C���ϻ����·�����})�r�������ԓchunk�Ĵ���������C���ijЩ������Ȼ�ǿ��õġ��@Ҳ��ζ������һ��chunk���������������xȡ�������Գ�����ö����C��Ď���������һ�������������������Ҫ�ڶ����C���g�M�У����@���҂����Խ��ܵġ�</P>
<P style="TEXT-INDENT: 2em"> 4.3��(chu��ng)�� ��� ��ƽ��</P>
<P style="TEXT-INDENT: 2em">Chunk�����Ą�(chu��ng)����Ҫ������ԭ��chunk�Ą�(chu��ng)��������������������ƽ��������</P>
<P style="TEXT-INDENT: 2em"> ��(d��ng)master��(chu��ng)��һ��chunk�r��������ʼ���Ŀյĸ��������ں�̎������������]�ׂ����أ�1.�M�����µ�chunk������Щ����ƽ���űP���gʹ��ֵ����Щchunkserver�ϡ��S���r�g������������@��ʹ��chunkserver�ĴűPʹ��څ����ͬ2.�M������ÿ��chunkserver�ϵ�������ļ���(chu��ng)����(sh��)�������mȻ��(chu��ng)�������Ǻܺ��ε��������������������������صČ���������������chunk�Ą�(chu��ng)��ͨ������錑�ߵ���Ҫ����(chu��ng)�����������҂���һ��append����x�Ĺ���ؓ�d��������һ��������������������͕�׃��ֻ�x�ġ�3.����ǰ��ӑՓ�������҂�ϣ���ڙC���g���chunk�ĸ���</P>
<P style="TEXT-INDENT: 2em"> ��(d��ng)chunk�Ŀ��Â�ݔ�(sh��)�����Ñ��O(sh��)����Ŀ��ֵ�r�����Master���M���؏�(f��)�������ж������ܵ�ԭ��?q��)������İl(f��)����chunkserver�����������chunkserver�������ij������ѱ���Ⱦ������һ�KӲ�P�����e�`�������û����Ñ��O(sh��)����Ŀ��ֵ׃�������������Ҫ�؏�(f��)�Ƶ�chunk����(j��)�ׂ����ش_����(y��u)�ȼ������һ�����������c��ݔ�(sh��)��Ŀ��ֵ���˶��������������҂��o��Щ�Gʧ��2��������chunk�ȁGʧ��1���ĸ��ߵă�(y��u)�ȼ����������������������������h�����ļ���chunk��������҂���������Щ��Ȼ���ڵ��ļ���chunk(����4.4��(ji��))������������������С��ʧ�������\���еđ�(y��ng)�ó����Ӱ�����҂������Щ�������Ñ��M�ȵ�chunk�ă�(y��u)�ȼ���</P>
<P style="TEXT-INDENT: 2em"> Master�x����߃�(y��u)�ȼ���chunk����ͨ�^�oij��chunkserver�l(f��)��ָ����V��ֱ�ӏ�һ���F(xi��n)�кϷ������п�ؐ��(sh��)��(j��)���M�п�¡��������ݵķ����c��(chu��ng)��������Ƶ�Ŀ�ˣ�ƽ���űPʹ�����������چ�chunkserver���M�е�clone������(sh��)�����ʹ��������ڲ�ͬ�C���g������˷�ֹclone�������͛]client�������������master����������Ⱥ�ѽ�(j��ng)ÿ��chunkserver��̎�ڻ�Ӡ�B(t��i)��clone������(sh��)���������ÿ��chunkserver߀������������clone�����ϵĎ��������ͨ�^��������Դchunkserver���xՈ�����</P>
<P style="TEXT-INDENT: 2em">��������master�������ԵČ������M����ƽ������������z�鮔(d��ng)ǰ�ĸ����ֲ����Ȼ����˸��õĴűP���gʹ�ú�ؓ�dƿ�i������������M���Ƅ�������������@���^���У�master�������һ���µ�chunkserver����������������µ�chunk�Լ��������صČ�����ʹ��æ�IJ����_��������һ���¸����ķ��������������ǰ�����ЩӑՓ�����������master����x��h���Ă��F(xi��n)�еĸ����������ͨ�����f����������ϲ�g��Щ����ڵ���ƽ���űP���e�ʵ�chunkserver�ϵ�chunk���@�ӿ���ʹ�űPʹ��څ��������</P>
<P style="TEXT-INDENT: 2em"> 4.4��������</P>
<P style="TEXT-INDENT: 2em">�ļ��h����GFS��������ጷſ��õ������惦����������@헹������t���ļ���chunk���e���������Օr�����҂��l(f��)�F(xi��n)������@�N����ʹ��ϵ�y(t��ng)�����θ��ɿ������</P>
<P style="TEXT-INDENT: 2em"> 4.4.1�C��</P>
<P style="TEXT-INDENT: 2em">��(d��ng)�ļ�����(y��ng)�ó���h���r����master�����@���h������������׃��һ�����⌑����־��������ļ������������h���������DZ���������һ�������h���r�g�����[�����Q����master���ļ�ϵ�y(t��ng)�M�г�Ҏ(gu��)����r������������h����Щ���ڕr�g���^3��(�@���r�g�ǿ������õ�)���[���ļ�����ڴ�֮ǰ���ļ���Ȼ�������ǂ��µ��������Q�M���xȡ�������������������ԭ�������Q��ȡ���h��������(d��ng)�[���ļ������ֿ��g�h��������������Ԫ��(sh��)��(j��)�����������@�Ӿ���Ч���Д������c����chunk���P(gu��n)(li��n)������</P>
<P style="TEXT-INDENT: 2em"> ��chunk����Ƶij�Ҏ(gu��)�����У�master�ҵ���Щ���K(�o�����κ��ļ����_)��������@Щ�K��Ԫ��(sh��)��(j��)�����cmaster����**����������Ϣ���������chunkserver����������е�chunk���ǂ��Ӽ���Ȼ��master������Щ����master��Ԫ��(sh��)��(j��)�г��F(xi��n)��chunk�Ę��R�����Chunkserver�Ϳ������ɵĄh���@Щchunk����Щ����������</P>
<P style="TEXT-INDENT: 2em"> 4.4.2ӑՓ</P>
<P style="TEXT-INDENT: 2em">�M�ܳ����O(sh��)Ӌ�Z���еķֲ�ʽ����������һ����Ҫ��(f��)�s��Q�������y�↖�}��������������҂��@�����Ǻܺ��ε���������҂����Ժ��ε��ҵ�����chunk���������ã��������������ֻ��master�S�o��һ���ļ�-chunkӳ������������҂������ҵ�����chunk�ĸ������������^�Ǵ����ÿ��chunkserver���ض�Ŀ��µ�linux�ļ�����κ�master��֪���ĸ��������������</P>
<P style="TEXT-INDENT: 2em"> �����������շ����ջش惦���g�cֱ�ӄh����ȣ��ṩ�ˎׂ���(y��u)�ݣ�1.�ڽ�(j��ng)�����F(xi��n)�M��ʧ���Ĵ�Ҏ(gu��)ģ�ֲ�ʽϵ�y(t��ng)������������Ǻ��ζ��ҿɿ���������Chunk��(chu��ng)��������ijЩchunkserver�ϳɹ���������һЩʧ���������@�Ӿ�����һЩmaster����֪���ĸ����������h����Ϣ���܁Gʧ������master���ӛ���ڳ��F(xi��n)ʧ���r�M���ذl(f��)�����������ṩ��һ�Nͬһ�Ŀ���ه������o�ø����ķ�ʽ�����2.�����惦���g�����cmaster��Ҏ(gu��)�ĺ��_��ӽY(ji��)����һ������������ֿ��g�����������cchunkserver�����֡���������ǽ���һ�K��(zh��)�е��������@���_�N����ƽ��������ֻ�Ю�(d��ng)master�������e�r�ŕ���(zh��)���������Master�Ϳ��Ԟ���Щ���Еr�g�����ԵĿ͑���Ո���ṩ���õ�푑�(y��ng)��3.���g���յ����t������IJ������D(zhu��n)�Ąh���ṩ��һ�����o�W(w��ng)����</P>
<P style="TEXT-INDENT: 2em"> ����(j��)�҂��Ľ�(j��ng)���������Ҫ��ȱ�c�ǣ���(d��ng)�űP���g�ܾo���r�����@�N�ӕr�����K���ÑűPʹ�õ��{(di��o)����������Щ�l����(chu��ng)���̈́h�����g�ļ��đ�(y��ng)�ó����܉��������ôűP���g���҂�ͨ�^��(d��ng)�фh�����ļ����ٴ΄h���r�������Ĵ惦���Ձ���Q�@�����}�����҂�Ҳ���S�Ñ��ڲ�ͬ�����ֿ��g��(n��i)ʹ�ò�ͬ����ݺͻ��ղ�����������Ñ�����ָ��ij��Ŀ䛘��µ��ļ���chunkʹ�ßo�����惦���κ��ѽ�(j��ng)�h�����ļ����������h�����ҏĮ�(d��ng)ǰ�ļ�ϵ�y(t��ng)�Џصׄh�����</P>
<P style="TEXT-INDENT: 2em"> 4.5�^�ڸ����z�y</P>
<P style="TEXT-INDENT: 2em">���chunkserverʧ����������ͣ�C���g�Gʧ��ijЩ���£�chunk�����Ϳ���׃?y��u)��^�ڵ���������ÿ��chunk���master�S�oһ���汾̖��^(q��)�����º��^�ڵĸ�����</P>
<P style="TEXT-INDENT: 2em"> ֻҪmaster��һ��chunk�ڙ�(qu��n)һ���µ���s��������ô���İ汾̖�͕����ӣ�Ȼ��֪ͨ�����M�и����������һ�µĠ�B(t��i)������Master�����и�������ӛ��@���µİ汾̖�����@�l(f��)�����κ�client��֪ͨ��ǰ����������Ҳ����client�_ʼ��chunk�Ќ���(sh��)��(j��)֮ǰ������������һ��������(d��ng)ǰ���������������chunk�汾̖�Ͳ��������¡���(d��ng)chunkserver�؆����߈������chunk�͌���(y��ng)�İ汾̖�ĕr�������master���z�yԓchunkserver�Ƿ�����^�ڸ����������master�l(f��)�F(xi��n)��Щ�汾̖��������ӛ������master���J�������ڙ�(qu��n)��s�rʧ�������������Բ��ø��ߵİ汾̖���ǂ��M�и���������</P>
<P style="TEXT-INDENT: 2em"> Masterͨ�^�����Ե��������Մh���^�ڸ������ڴ�֮ǰ����������ڿ͑��ˌ���ԓchunk��Ո��master��ֱ�ӌ��^�ڸ�����(d��ng)�������������M��̎�����������������һ�N���o��ʩ������(d��ng)master֪ͨ�͑����ǂ�chunkserver����ijchunk����s���߮�(d��ng)����clone������chunkserver����һ��chunkserver���xȡchunk�r���������chunk�İ汾̖�����ڃ�(n��i)�������(d��ng)clinet��chunkserver��(zh��)�в����r�����Ǖ���C�汾̖�����@�Ӿ�ʹ�����������L�����µĔ�(sh��)��(j��)��</P>
<P style="TEXT-INDENT: 2em"> 5.���e���\��</P>
<P style="TEXT-INDENT: 2em">���O(sh��)Ӌϵ�y(t��ng)�r������һ����������(zh��n)�����l���ĽM��ʧ�����M���Ĕ�(sh��)�����|(zh��)��ʹ���@Щ���}׃��һ�N���B(t��i)�������Ǯ���������҂�������ȫ���ΙC��Ҳ������ȫ���δűP���M��ʧ������(d��o)��ϵ�y(t��ng)����������������Ǔp�Ĕ�(sh��)��(j��)�������҂�ӑՓ������挦�@Щ����(zh��n)����Լ���(d��ng)�������ɱ���İl(f��)���r����ϵ�y(t��ng)�н�������Щ���߁��\�����}����</P>
<P style="TEXT-INDENT: 2em"> 5.1�߿�����</P>
<P style="TEXT-INDENT: 2em">��GFS�Ĕ�(sh��)���_����(w��)�����������κΕr�g������һЩ�Dz����õ�������҂�ͨ�^�ɂ�������Ч�IJ��ԁ���������ϵ�y(t��ng)�ĸ߿����ԣ����ٻ֏�(f��)�͂��������� </P>
<P style="TEXT-INDENT: 2em">5.1.1���ٻ֏�(f��)</P>
<P style="TEXT-INDENT: 2em">Master��chunkserver���O(sh��)Ӌ�ßoՓ��ô�ӵر��Kֹ��������������ڎ����(n��i)�֏�(f��)�����Ġ�B(t��i)���������������������҂����]�Ѕ^(q��)�������ͮ����ĽKֹ���������(w��)��ͨ������ͨ�^�����M�́��P(gu��n)�]���������͑��˺���������(w��)����Ո�r�����(j��ng)�vһ��С��ͣ�D������Ȼ�����B�ǂ��؆���ķ���(w��)�����M����ԇ�������6.2.2������^�y���Ć��ӕr�g����</P>
<P style="TEXT-INDENT: 2em"> 5.1.2chunk���</P>
<P style="TEXT-INDENT: 2em">����֮ǰӑՓ�ģ�ÿ��chunk����ڲ�ͬ�C���ϵĶ���chunkserver����������Ñ������ڲ�ͬ���ֿ��g��(n��i)�O(sh��)�ò�ͬ�Ă�ݼ��e����Ĭ�J��3.��(d��ng)chunkserver�x������ͨ�^�z�͙z�y��ij��chunk�p�ĺ�(5.2��(ji��))�������master����¡�F(xi��n)�еĸ���ʹ�ø����Ĕ�(sh��)���ֳ���������M�ܸ����ѽ�(j��ng)�ܺõĝM�����҂��������҂�߀̽��һЩ�����ľ���ͬ�Ȼ��߸���code�Ŀ�C�����������������M���҂�?n��i)������L��ֻ�x�惦�����҂��������҂��ķdz���ɢ��ϵ�ϵ�y(t��ng)�Ќ��F(xi��n)�@Щ����(f��)�s������ģʽ�Ǿ�������(zh��n)�Ե��ǿɹ������������҂���ؓ�d��Ҫ��append���x����������С���S�C��������</P>
<P style="TEXT-INDENT: 2em"> 5.1.3master���</P>
<P style="TEXT-INDENT: 2em">���˿ɿ�������master�Ġ�B(t��i)��Ҫ�M�Ђ���������IJ�����־�͙z���c����ڶ��_�C�������������ڠ�B(t��i)��׃��ֻ�Ю�(d��ng)���IJ�����־�����뵽���شűP�����е��h�̂�ݺ�����������J�������������˺�����Ҋ�������master����ؓ؟(z��)�M�и��N���_��ӱ��磺��������������߀Ҫؓ؟(z��)̎�����е�׃�������(d��ng)��ʧ�������������؆����������������ڵęC������Ӳ�P�����������������GFS�ıO(ji��n)���O(sh��)ʩ�����Â�ݵIJ�����־�ڄe̎�؆�һ���µ�master�M�������Client�H�Hʹ��master��һ���������Q(����gfs-test)���L��������@��һ��DNS���Q�����master�����²���һ���µęC�������������Ը�׃����</P>
<P style="TEXT-INDENT: 2em"> �������������(d��ng)��master down��֮������߀�ж���Ӱ��master�����ṩ���ļ�ϵ�y(t��ng)��ֻ�x�L�������������Ӱ������������R����������@��ζ���������ܱ���masterҪ����һЩ������ͨ�����������ǎ��������������Щ���ٰl(f��)��׃�����ļ����߲������p�^�r�đ�(y��ng)�ó�����f�������������x�����Ŀ�����������H�ϣ�����ļ���(n��i)���Ǐ�chunkserver���xȡ���������(y��ng)�ó����������^�ڵ��ļ���(n��i)�������ļ�Ԫ��(sh��)��(j��)�����ڶ��ڃ�(n��i)���^�ڵ���������Ŀ䛃�(n��i)�ݻ����L��������Ϣ����</P>
<P style="TEXT-INDENT: 2em"> ���˱����Լ��Č��r�����Ӱ�ӷ���(w��)�����xȡ�������L�IJ�����־�ĸ�������Ȼ������master�ǘӌ��@Щ׃�����Б�(y��ng)�����Լ��Ĕ�(sh��)��(j��)�Y(ji��)��(g��u)���������c��masterһ�ӣ���Ҳ���چ��ӕr��chunkserver����(sh��)��(j��)����λchunk�ĸ����������Ҳ��ͬ�������Q������Ϣ�ԱO(ji��n)�������Ġ�B(t��i)��ֻ������master�Q����(chu��ng)�����߄h�������r����λ����Ϣ���r�����������ه����master�������</P>
<P style="TEXT-INDENT: 2em"> 5.2��(sh��)��(j��)������</P>
<P style="TEXT-INDENT: 2em">ÿ��chunkserverͨ�^У�́�z�y�惦��(sh��)��(j��)�еēp������GFS��Ⱥͨ�����зֲ��ڎװ��_�C���ϵĔ�(sh��)ǧ�KӲ�P�����@�����͕���(j��ng)�����F(xi��n)��(d��o)��(sh��)��(j��)�p�Ļ�Gʧ��Ӳ�Pʧ���������҂����ԏ�chunk�����������л֏�(f��)���p�ĵĔ�(sh��)��(j��)�����������ͨ�^��chunkserver�g���^��(sh��)��(j��)��z�y��(sh��)��(j��)�p���Dz��F(xi��n)����������⣬�з���Ă����Ȼ�����ǺϷ��ģ�����(j��)GFS��׃���Z�x������������ǰ���ᵽ��ԭ���Ե�record append����������������C���и�������ȫһ�µ�������ÿ��chunkserver���ͨ�^�S�oһ���z�́���������C���Լ��Ŀ�ؐ�������ԡ�</P>
<P style="TEXT-INDENT: 2em"> һ��chunk�����֞�64kb��С�ĉK���ÿ���K��һ������(y��ng)��32bit��У�͡��c������Ԫ��(sh��)��(j��)һ���������У���c�Ñ���(sh��)��(j��)���x��������������ڃ�(n��i)�����������ͬ�rͨ�^��־�M�г־û��惦���</P>
<P style="TEXT-INDENT: 2em"> �����x������chunkserver����Ո����(������һ��client����������chunkserver)���ؔ�(sh��)��(j��)ǰ���������Ҫ�z��c�xȡ߅���دB����Щ��(sh��)��(j��)���У����������chunkserver�������p�Ĕ�(sh��)��(j��)�����������C����ȥ����������һ���K��У���cӛ��еIJ�һ�����chunkserver����Ո���߷���һ���e�`��ͬ�r��master����@����ƥ�����֮��Ո���ߕ������������xȡ��(sh��)��(j��)������master�t��������������clone�@��chunk������(d��ng)�@���Ϸ����¸�����(chu��ng)���ɹ�������master���治ƥ����ǂ�chunkserver�l(f��)��ָ��h�����ĸ��������</P>
<P style="TEXT-INDENT: 2em"> У�͌����x���ܵ�Ӱ푺�С��������飺�҂��ֵ��x�������ٿ�Խ�����K������҂�ֻ��Ҫ�xȡ�����ٵ��~�┵(sh��)��(j��)���M����C�������GFS client���aͨ�^�M����У�߅���ό��R�x����������_�N����������chunkserver��У�͵IJ��Һͱ��^����Ҫ�κε�IO����������У�͵�Ӌ��Ҳ�����cIO�����دB�M�����</P>
<P style="TEXT-INDENT: 2em"> У��Ӌ�㌦��append�ļ�ĩβ�Č������M�����e�ă�(y��u)������������ڹ���ؓ�d��ռ��(j��)�˽y(t��ng)�ε�λ�������҂��H�H�����Եĸ������һ��У�K��У�ֵ��ͬ�r����Щappendβ����ȫ�µ�У�KӋ������У�ֵ���������ʹ���һ�����ֵ�У�K�ѽ�(j��ng)�p��������҂��F(xi��n)�ڟo���z�y��������ô��Ӌ�������У�͌������c�惦��(sh��)��(j��)ƥ�������ô��(d��ng)�@���K�´α��xȡ�r���Ϳ��ԙz�y���@���p������(Ҳ�����f�@�ﲢ�]����C���һ���K��У�ֵ������ֻ�Ǹ�������ֵ�����Ҳ�����f�@��ʡȥ����C���^��������e�����Ӽ��O(sh��)���һ��У�K���F(xi��n)���e�`�������҂���У�ֵӋ��r�������Ե����Ҳ�����f�´�Ӌ�㲻������Ӌ���Ѵ��ڵ��@���֔�(sh��)��(j��)��У����������@��ԓ�p�ľ��^�m(x��)������У���������P(gu��n)�I������@������������͵�У��Ӌ�㷽ʽ)</P>
<P style="TEXT-INDENT: 2em"> �c֮�������������һ���������߸��w��һ���F(xi��n)��chunk��߅�������҂���������xȡ����C����߅���ϵĵ�һ�������һ���K���Ȼ���(zh��)�Ќ������������Ӌ���ӛ��µ�У�������������ڸ��w����֮ǰ����C��һ�������һ���K��������µ�У�;Ϳ����[�ص���Щδ�����w�ą^(q��)��Ĕ�(sh��)��(j��)�p��������(����@��]�в�������Ӌ�㷽ʽ��������Ǹ��w����append���ԬF(xi��n)�еęz�;��������K�ě]������ȡ�����֔�(sh��)��(j��)��У���������������Ӌ��)����</P>
<P style="TEXT-INDENT: 2em"> �ڿ��e���g��chunkserver���Ԓ�����C̎�ڷǻ�Ӡ�B(t��i)��trunk�ă�(n��i)����������@���S�҂��z�y����Щ���ٱ��xȡ�Ĕ�(sh��)��(j��)�ēpʧ����һ���p�ı��l(f��)�F(xi��n)�����master�Ϳ��Ԅ�(chu��ng)��һ���µ�δ�p�ĸ������҄h���p�ĵĸ����������@�ͱ�����һ�������S�ĉĉK�_�^master�������֮�Ԟ�K�����ĺõĸ������</P>
<P style="TEXT-INDENT: 2em"> 5.3�\���</P>
<P style="TEXT-INDENT: 2em">ȫ���Ԕ�����\���Ե���־�Ժ�С�ijɱ����������چ��}�ֽ�����{(di��o)ԇ�����ܷ����ϲ��ɹ����Ď�����������]����־���ͺ��y������Щ�C���gżȻ���F(xi��n)�IJ����؏�(f��)�Ľ����������GFS����һ���\����־�Á�ӛ䛺ܶ���Ҫ�¼�(����chunkserver�Ć���ֹͣ)�Լ�����RPCՈ��͑�(y��ng)������@Щ�\����־�������ɵĄh������Ӱ�ϵ�y(t��ng)�������\�С�Ȼ���������ֻҪ�űP���g���S�������҂����M�������@Щ��־��</P>
<P style="TEXT-INDENT: 2em"> RPC��־���������е�Ո���푑�(y��ng)��Ϣ���������x�����ļ���(sh��)��(j��)������ͨ�^ƥ��Ո���푑�(y��ng)��������ͬ�C���ϵ�RPC��־������҂���������(g��u)�������������vʷ���\��һ�����}�������@Щ��־Ҳ�����Á��M��ؓ�d�yԇ�����ܷ�����</P>
<P style="TEXT-INDENT: 2em"> �����־���������������ˌ���־�������ܵ�Ӱ��Ǻ�С�������õ��ĺ�̎�s�Ǵ����������������¼�Ҳ�������ڃ�(n��i)�����������������ڳ��m(x��)���ھ��O(ji��n)�������</P>
<P style="TEXT-INDENT: 2em">6.�y��</P>
<P style="TEXT-INDENT: 2em">���@һ��(ji��)����҂���һЩСҎ(gu��)ģ�Ĝyԇ��չʾGFS�ܘ�(g��u)�͌��F(xi��n)���е�һЩƿ�i�����һЩ��(sh��)�ց�Դ��google�Č��H��Ⱥ��</P>
<P style="TEXT-INDENT: 2em"> 6.1СҎ(gu��)ģ�yԇ</P>
<P style="TEXT-INDENT: 2em">�҂���һ����һ��master�������ɂ�master��ݣ�16��chunkserver��16��client�M�ɵ�GFS��Ⱥ���M�������ܜy��������@�������Ǟ��˷���yԇ���������H�еļ�Ⱥͨ�����Д�(sh��)�ق�chunkserver�����(sh��)�ق�client��</P>
<P style="TEXT-INDENT: 2em"> ���ЙC�����������������p��PIII 1.4GHz̎������2GB��(n��i)������ɂ�80G��5400rpmӲ�P�����Լ�100Mbpsȫ�p����̫�W(w��ng)�B�ӵ�HP2524���Q�C�����������19��GFS����(w��)���B����һ�����Q�C����������16���͑����B������һ���ϡ��ɂ����Q�C��1Gbps�ľ�·�B��������</P>
<P style="TEXT-INDENT: 2em"> 6.1.1�x����</P>
<P style="TEXT-INDENT: 2em">N���͑��ˏ��ļ�ϵ�y(t��ng)�в��l(f��)�x����ÿ���͑�����һ��320GB���ļ��������S�C4MB�M���xȡ����Ȼ���؏�(f��)256��������@��ÿ���͑��ˌ��H���xȡ��1GB��(sh��)��(j��)��Chunkserver����ֻ��32GB��(n��i)������������҂���Ӌ��linux��buffer cache�������10%�������ʡ��҂��ĽY(ji��)����(y��ng)ԓ�ܽӽ�һ�����o����ĽY(ji��)��������� </P>
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515601aT8M.png" target=_blank><IMG style="WIDTH: 583px; HEIGHT: 236px" height=236 src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515601aT8M.png" width=574 border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em">�D3(a)չʾ�ˌ���N���͑��˵Ŀ����xȡ�����Լ�������Փ�ϵĘO�������(d��ng)2�����Q�Cͨ�^һ��1Gbps���·�B�ӕr��������ĘO��ֵ��125MB/s����͑���ͨ�^100Mbps�B����������ô�Q�Ɇ��͑��˵ĘO����12.5MB/s����(d��ng)ֻ��һ���͑������xȡ�r���^�쵽���xȡ������10MB/s����_���ˆ��͑��˘O��80%����(d��ng)16���xȡ�ߕr��������xȡ���ʵ�94 MB/s������_�����·�O��(125MB/s)��75%����Q�Ɇ��͑��˾���6 MB/s��Ч�ʏ�80%������75%�������������S���xȡ�ߵ����ӣ������x�ߏ�ͬһ��chunkserver���l(f��)�x��(sh��)��(j��)�ĸ���Ҳ�S֮׃��������</P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">6.1.2������</P>
<P style="TEXT-INDENT: 2em">N���͑��˲�����N����ͬ���ļ�����(sh��)��(j��)��ÿ���͑�����1MB�Ć�������������һ�����ļ�����1GB��(sh��)��(j��)�������������Č������Լ�������Փ�ϵĘO����D3(b)��ʾ������O��ֵ׃����67 MB/s��������҂���Ҫ��ÿ���ֹ�(ji��)���뵽16��chunkserver�е�3��������ÿ������12.5MB/s��ݔ���B��������</P>
<P style="TEXT-INDENT: 2em"> ���͑��˵Č���������6.3 MB/s����������ǘO��ֵ��һ�롣��Ҫԭ�����҂��ľW(w��ng)�j(lu��)�f(xi��)�h�������������ܳ�������҂�����chunk������(sh��)��(j��)���͵���ˮ��ģʽ������(sh��)��(j��)��һ���������f����һ�����������t���������w�Č������������</P>
<P style="TEXT-INDENT: 2em"> ����16���͑����������w�Č��������_����35 MB/s�����ƽ��ÿ���͑���2.2 MB/s,�������Փ�O��һ�롣�c������������������S�����ߵ�������������������ߏ�ͬһ��chunkserver���l(f��)����(sh��)��(j��)�ĸ���Ҳ�S֮׃������������⌦��16�����߱�16���x�߸����a(ch��n)����ײ���������ÿ�����ߌ��P(gu��n)(li��n)��3����ͬ�ĸ������</P>
<P style="TEXT-INDENT: 2em"> ���߱��҂�������Ҫ�����ڌ��H����������@߀ĩ׃��һ����Ҫ���}�������M�����������ӆ��͑��˵��ӕr������Ǯ�(d��ng)ϵ�y(t��ng)�挦�����͑��˕r���係�Č��뎧�����]���@����Ӱ����</P>
<P style="TEXT-INDENT: 2em"> 6.1.3ӛ���</P>
<P style="TEXT-INDENT: 2em">�D3(c)չʾ��record append�����ܡ�N���͑�������ļ����е�append�����������ȡ�Q�ڱ�����ԓ�ļ�����ǂ�chunk����Щchunkserver���c�͑��˵Ĕ�(sh��)Ŀ�o�P(gu��n)���������(d��ng)ֻ��һ���͑��˕r�������_��6.0MB/s��������(d��ng)��16���͑��˕r�ͽ�����4.8 MB/s����Ҫ�����ړ����Լ���ͬ�Ŀ͑��˵ľW(w��ng)�j(lu��)��ݔ���ʲ�ͬ��ɵ����</P>
<P style="TEXT-INDENT: 2em"> �҂��đ�(y��ng)�ó���A���ڲ��Є�(chu��ng)�������@�ӵ��ļ����Q��Ԓ�f������N���͑�����M�������ļ�����append�����@��N��Mͨ���ǎ�ʮ�����װٴ�С����������҂��Č���г��F(xi��n)��chunkserver�ľW(w��ng)�j(lu��)�������}�ڌ��H�в�����һ���@���Ć��}��������鮔(d��ng)һ���ļ���chunkserver���^��æ�ĕr��������������ȥ����һ������</P>
<P style="TEXT-INDENT: 2em">6.2�F(xi��n)���ļ�Ⱥ</P>
<P style="TEXT-INDENT: 2em">�҂��x����google��(n��i)��ʹ�õăɂ���Ⱥ�M�Мyԇ�������Ƶ���Щ��Ⱥ��һ�������������ȺA��Ҫ����100�������̵��ճ��аl(f��)�������Ĕ�(sh��)TB�Ĕ�(sh��)��(j��)���xȡ��(sh��)MB�Ĕ�(sh��)��(j��)�������@Щ��(sh��)��(j��)�M���D(zhu��n)�����߷������Ȼ�Y(ji��)���ٌ��ؼ�Ⱥ����ȺB��Ҫ���ڮa(ch��n)Ʒ��(sh��)��(j��)̎����������������΄�(w��)���m(x��)�r�g���L�����m(x��)�������ɺ�̎�픵(sh��)TB�Ĕ�(sh��)��(j��)�������ֻ��ż��������Ҫ�˞�ą��c�����@�ɷN��r������΄�(w��)�����ɷֲ��ڶ����C���ϵĺ��M�̽M�ɣ��������е��x���ܶ��ļ������� </P>
<P style="TEXT-INDENT: 2em">6.2.1�惦</P>
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515659fOeb.png" target=_blank><IMG src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515659fOeb.png" border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em"> �������ǰ5���ֶ���չʾ�ģ��ɂ���Ⱥ���Д�(sh��)�ق�chunkserver����֧��TB����Ӳ�P���g����������g�ѽ�(j��ng)�����ʹ�õ�߀�]ȫ�M�����õĿ��g����chunk�����и��������ͨ���ļ��������������������@�ɂ���Ⱥ���H�քe�惦��18TB��52TB�Ĕ�(sh��)��(j��)������� </P>
<P style="TEXT-INDENT: 2em">�@�ɂ���Ⱥ���ļ���(sh��)Ŀ�ܽӽ�����M��B��Ⱥ�д��������ļ�(��Щ�ѽ�(j��ng)���h�����߱��°汾�ļ�����Q�����g߀�]�б�ጷŵ��ļ�)�����������и����trunk�����������������ļ�ͨ������</P>
<P style="TEXT-INDENT: 2em"> 6.2.2Ԫ��(sh��)��(j��)</P>
<P style="TEXT-INDENT: 2em">���е�Chunkserver�����惦�˔�(sh��)ʮG��Ԫ��(sh��)��(j��)������������Ñ���(sh��)��(j��)��64kb�K��У������Chunkserver��Ψһ��������Ԫ��(sh��)��(j��)����4.5��(ji��)ӑՓ��chunk�İ汾̖���</P>
<P style="TEXT-INDENT: 2em"> ������master�ϵ�Ԫ��(sh��)��(j��)Ҫ��СһЩ��ֻ�Д�(sh��)ʮMB����ƽ����ÿ���ļ�ֻ��100�킀�ֹ�(ji��)���@Ҳ���÷����҂���master�ă�(n��i)�治���ɞ錍�H��ϵ�y(t��ng)�������Ƶ�����������ÿ���ļ���Ԫ��(sh��)��(j��)��Ҫ����ǰ�Y���s��ʽ�惦���ļ����Q�������߀��һЩ������Ԫ��(sh��)��(j��)�����ļ��������������(qu��n)������ļ���chunk��ӳ���Լ�chunk�Į�(d��ng)ǰ�汾���������⌦��ÿ��chunk�҂�߀�惦�ˮ�(d��ng)ǰ�ĸ���λ���Լ����ڌ��F(xi��n)���r��(f��)�Ƶ�����Ӌ��(sh��)��</P>
<P style="TEXT-INDENT: 2em"> ÿ��������server(chunkserver��master)ֻ��50-100MB��Ԫ��(sh��)��(j��)���������������֏�(f��)�Ǻܿ�ģ���server���ԑ�(y��ng)���ԃǰֻ��Ҫ������犵ĕr�g�Ϳ���������Ӳ�P���x���������Ȼ�����master�Ć��ӿ���Ҫ��һЩ��ͨ��߀��Ҫ30-60������е�chunkserver�@��chunk��λ����Ϣ������</P>
<P style="TEXT-INDENT: 2em"> 6.2.3�x������</P>
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515702yJA8.png" target=_blank><IMG src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515702yJA8.png" border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em"> ��3չʾ�˲�ͬ�r�ڵ��x�����ʡ��M���@Щ�y���r�����ɂ���Ⱥ���ѽ�(j��ng)�\���˴�sһ��(���˸��µ����°汾��GFS�����@�ɂ���Ⱥ���؆��^)�����</P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">�Ć����_ʼ�����ƽ��������С��30MB/s������(d��ng)�҂��M���@Щ�y���r���������ȺB������100MB/s�������M���ܼ��Č�����������ͬ�r�a(ch��n)����300MB/s�ľW(w��ng)�j(lu��)ؓ�d����錑�����������o3������������</P>
<P style="TEXT-INDENT: 2em"> �x����Ҫ�h���ڌ��������������҂�������ǘ���������������ؓ�d�M������������Ҫ���ڌ������@�ɂ���Ⱥ��̎�ڷ��ص��x����������������ǣ�A�ѽ�(j��ng)���^ȥ��һ�������оS����580MB/s���x��������������ľW(w��ng)�j(lu��)���ÿ���֧��750MB/s������������ѽ�(j��ng)����������YԴ��B��Ⱥ��֧��1300 MB/s�ķ�ֵ�x����������Ǒ�(y��ng)��ֻʹ����380 MB/s��</P>
<P style="TEXT-INDENT: 2em"> 6.2.4 masterؓ�d</P>
<P style="TEXT-INDENT: 2em">��3Ҳ�����l(f��)�ͽomaster�IJ������ʴ����ÿ��200-500����������Master�����p��̎���@�����e�����ʣ���ˌ����@Щ����ؓ�d���f����������ɞ�ƿ�i��</P>
<P style="TEXT-INDENT: 2em"> �����ڰ汾��GFS��������masterż�����ɞ�ijЩ����ؓ�d��ƿ�i�����˲����ļ���������M�����ĕr�g�ھ��Ŀ�(������ǧ�f���ļ�)���M�о��Ԓ�����������������҂���׃��master�Ĕ�(sh��)��(j��)�Y(ji��)��(g��u)�����ʹ֮���������ֿ��g��(n��i)�M����Ч�Ķ�����������F(xi��n)�������Ժ��ε�֧��ÿ����ǧ�ε��ļ��L����������Ҫ��Ԓ���҂�߀�����Mһ���������ֿ��g��(sh��)��(j��)�Y(ji��)��(g��u)ǰ���ṩ���ֲ��Ҿ������</P>
<P style="TEXT-INDENT: 2em"> 6.2.5 �֏�(f��)�r�g</P>
<P style="TEXT-INDENT: 2em">һ�_Chunkserverʧ�������������Щchunk�ĸ�����(sh��)�͕����������������M��clone�ԾS�������ĸ�����(sh��)�������֏�(f��)�@Щchunk�ĕr�gȡ�Q���YԴ�Ĕ�(sh��)������һ������������҂��P(gu��n)�]��ȺB�е�һ��chunkserver���ԓchunkserver�����15000��chunk������600GB�Ĕ�(sh��)��(j��)������p�ٌ��ڑ�(y��ng)�ó����Ӱ��Լ����{(di��o)�țQ���ṩ��أ��҂���Ĭ�J����(sh��)�O(sh��)�Ì���Ⱥ�IJ��l(f��)clone����������91��(ռchunkserver����(sh��)��40%),ͬ�rÿ��clone��������������6.25MB/s(50Mbps)�����е�chunk��23.2��犃�(n��i)���֏�(f��)��������������440MB/s�������</P>
<P style="TEXT-INDENT: 2em"> ����һ������У��҂��P(gu��n)���˃ɂ�chunkserver����ÿ������16000��chunk����660GB�Ĕ�(sh��)��(j��)������@��ʧ��ʹ��266��chunk���͵���һ���������������ǃɷ�犃�(n��i)�������ͻ֏�(f��)��������2�������������@�Ӿ���Ⱥ�܉�������һ��chunkserver�l(f��)��ʧ����������a(ch��n)����(sh��)��(j��)�Gʧ������</P>
<P style="TEXT-INDENT: 2em"> 6.3 ����ؓ�d����</P>
<P style="TEXT-INDENT: 2em">���@һ��(ji��)��������҂����^�m(x��)�ڃɂ��µļ�Ⱥ�ό�����ؓ�d�M�м��µČ��ȷ�����������ȺX�������о��_�l(f��)��������ȺY�����ڮa(ch��n)Ʒ��(sh��)��(j��)̎���������</P>
<P style="TEXT-INDENT: 2em">6.3.1 �������f��</P>
<P style="TEXT-INDENT: 2em">�@Щ�Y(ji��)��ֻ�����˿͑��ˮa(ch��n)����Ո����������������ӳ�ˑ�(y��ng)�ó���Č������ļ�ϵ�y(t��ng)�Ĺ���ؓ�d�������������ˈ�(zh��)�п͑��˵�Ո���M�е�server�g��Ո�����ǃ�(n��i)���ĺ��_�������������猑���ͻ�������ƽ�⡣</P>
<P style="TEXT-INDENT: 2em"> ����IO�����Ľy(t��ng)Ӌ�Ǐ�GFS��server��PRCՈ����־������(g��u)�������ġ�����������Ӳ���������GFS�͑��˴��a���܌�һ���x������֞����RPCՈ������҂�ͨ�^�����Ɣ��ԭʼՈ������҂����L��ģʽ�߶ȵij�ʽ����ϣ��ÿ���e�`�����Գ��F(xi��n)����־�С���(y��ng)�ó����@ʽ��ӛ䛿����ṩ�����_�Ĕ�(sh��)��(j��)���������¾��g�Լ��؆������\���еĿ͑�����߉���Dz������@��������������������ڙC����(sh��)�ܶ���������ռ��@Щ��(sh��)��(j��)Ҳ��׃�úܱ������</P>
<P style="TEXT-INDENT: 2em"> ��Ҫע����ǣ����܌��҂��Ĺ���ؓ�d�^��һ�㻯��������GFS�͑�(y��ng)�ó�������google��ȫ���Ƶ�������(y��ng)�ó�����ᘌ�GFS�M�Ќ��T��(y��u)�����������ͬ�rGFSҲ�nj��T���@Щ��(y��ng)�ö��O(sh��)Ӌ��������@�N���Ӱ푿���Ҳ������һ����ļ�ϵ�y(t��ng)���䑪(y��ng)�ó���������������@�NӰ푿��ܲ������҂��������������ǘ�����</P>
<P style="TEXT-INDENT: 2em"> 6.3.2 chunkserverؓ�d</P>
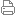
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515749f0m1.png" target=_blank><IMG src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515749f0m1.png" border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em"> ��4չʾ�˲�������(j��)��С�ķֲ��������x�����Ĵ�С���F(xi��n)���p��ֲ�������С���x����(С��64kb)��������Щ�ڴ����ļ��в���СƬ��(sh��)��(j��)���S�C�x�͑������������x����(���^512kb)�����ڴ�Խ�����ļ��ľ����x��������</P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">��ȺY�д������x�����]�з��ؔ�(sh��)��(j��)����҂���(y��ng)�ó��������������ڮa(ch��n)Ʒϵ�y(t��ng)�����������(j��ng)��ʹ���ļ��������a(ch��n)�����M�������������a(ch��n)�߲��е����ļ���append��(sh��)��(j��)����������M�߄t���ļ�β���x��(sh��)��(j��)���Еr��������������M�߳��^�����a(ch��n)�ߣ��͛]�Д�(sh��)��(j��)�����������ȺX���ٳ��F(xi��n)�@�N��r�������������Ҫ���Á��M�ж��ڔ�(sh��)��(j��)�����������������L�ڵķֲ�ʽ��(y��ng)�á�</P>
<P style="TEXT-INDENT: 2em"> �������Ĵ�СҲ���F(xi��n)���p��ֲ���������͵Č�����(���^256KB)ͨ�������ڌ������ߵľ��_�������Щ���_���ٔ�(sh��)��(j��)�Č������ߣ��z���c���߽�(j��ng)���Ե�ͬ�����ߺ��εĔ�(sh��)��(j��)���ɽM����С�͵Č�����(����64KB)�������</P>
<P style="TEXT-INDENT: 2em"> ����ӛ䛵�append��Y��Ⱥ��X��Ⱥ���Կ�������Ĵ�record append����������ʹ��Y��Ⱥ�Įa(ch��n)Ʒϵ�y(t��ng)�������ᘌ�GFS�M���˸���ă�(y��u)�������</P>
<P style="TEXT-INDENT: 2em"> <A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515839IoGo.png" target=_blank><IMG src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515839IoGo.png" border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em"> ��5չʾ�˲�ͬ��С�Ĕ�(sh��)��(j��)��ݔ�������������ڸ��N�������f��������͵IJ���(���^256KB)��(g��u)���˴ֵĔ�(sh��)��(j��)��ݔ���������С��(����64KB)���x�����mȻ��ݔ�˱��^�ٵĔ�(sh��)��(j��)�����ڔ�(sh��)��(j��)�x��Ҳռ��(j��)���ஔ(d��ng)?sh��)�һ���֣���Ҫ�������S�Cseek��ɵ��������</P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">6.3.4 append�cwrite</P>
<P style="TEXT-INDENT: 2em">ӛ�append�����������đ�(y��ng)�����������҂��Įa(ch��n)Ʒϵ�y(t��ng)��������ڼ�ȺX���f�����ֹ�(ji��)��ݔ��������write�cappend�ı�����108��1������(j��)������(sh��)���������ı�����8��1�������ڼ�ȺY�������׃����3.7��1��2.5��1�������@�ɂ���Ⱥ���f����������append������Ҫ��write������һЩ��������(sh��)�ı�Ҫ�h�����ֹ�(ji��)��(sh��)�ı������f������append�������ֹ�(ji��)��(sh��)Ҫ����write�����������ڼ�ȺX���f���ڜy�����g��ӛ�append����Ҫ��һЩ������@�����������о������⾏�_��С�O(sh��)�õđ�(y��ng)�ó�����ɵ��������</P>
<P style="TEXT-INDENT: 2em"> �����������������҂��Ĕ�(sh��)��(j��)׃������̎��֧���λ�����Ӷ������،�{writeҲ��������}�������҂��y�������������ϵĔ�(sh��)��(j��)�،���(sh��)����������ڼ�ȺX���f�����ֹ�(ji��)��СӋ���Ԓ�،����ռ��������(sh��)��(j��)׃����0.0001%����Բ�������(sh��)Ӌ�㣬���С��0.0003%���������Y��Ⱥ���f���@�ɂ���(sh��)�ֶ���0.05%�������M���@Ҳ�������߀��Ҫ�����҂��������������Y(ji��)���@ʾ���ֵ��،��������e�`���߳��r��(d��o)�µĿ͑����،����a(ch��n)�����������������ǹ���ؓ�d��һ��������������nj�����ԇ�C��������</P>
<P style="TEXT-INDENT: 2em"> 6.3.4 masterؓ�d</P>
<P style="TEXT-INDENT: 2em"><A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515885ZBq8.png" target=_blank><IMG src="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/201101/20/25098298_1295515885ZBq8.png" border=0 ; .load="imgResize(this, 650);"></A></P>
<P style="TEXT-INDENT: 2em"> ��6չʾ�ˌ���master���NՈ����͵�������������Ո���Ǟ��˵õ�chunkλ���Լ���(sh��)��(j��)׃����Ҫ����s������Ϣ����</P>
<P style="TEXT-INDENT: 2em"> ���Կ�����ȺX��Y��deleteՈ���ϵ����ƅ^(q��)�e������鼯ȺY�ϴ惦�Įa(ch��n)Ʒ��Ϣ�������Ե����ɱ��°汾��(sh��)��(j��)����Q����@Щ��ͬ���[����openՈ���У�����ϰ�Ĕ�(sh��)��(j��)�ڱ����ĕr��Ĵ��_�����б��[ʽ�Ąh��(����cUnix�ġ�w�����_ģʽ)������</P>
<P style="TEXT-INDENT: 2em"> ����ƥ���ļ���һ�������ls��ģʽƥ��Ո����������Ո���������������Ҫ̎���ֵܴ����ֿ��g�����˿����Ǻܰ��F���������ڼ�ȺY�Ͽ��Ը��l���ؿ�����������Ԅӻ��Ĕ�(sh��)��(j��)̎���΄�(w��)�����˽�������(y��ng)�ó���Ġ�B(t��i)������Ҫ�z���ļ�ϵ�y(t��ng)�е�ijЩ��������c����ȣ���ȺX��Ҫ�����@ʽ���Ñ����ƶ����ѽ�(j��ng)��ǰ֪������Ҫ���ļ������Q����</P>
<P style="TEXT-INDENT: 2em"></P>
<P style="TEXT-INDENT: 2em">7.��(j��ng)�</P>
<P style="TEXT-INDENT: 2em">�ژ�(g��u)���Ͳ���GFS���^���У��҂����Y(ji��)���˺ܶཛ(j��ng)���������^�c�ͼ��g(sh��)�����</P>
<P style="TEXT-INDENT: 2em"> �������GFSֻ�ǿ��]�����҂��a(ch��n)Ʒϵ�y(t��ng)�ĺ���ļ�ϵ�y(t��ng)����S���r�g����������_ʼ���о����_�l(f��)��ʹ������һ�_ʼ��������֧�����(qu��n)������quota�@Щ�|����������ǬF(xi��n)���������ѽ�(j��ng)�����������a(ch��n)Ʒϵ�y(t��ng)�Ǻ������Ƶ������������Ñ�s���ǡ������Ҫ������O(sh��)ʩ�������Ñ��g�ĸɔ_��</P>
<P style="TEXT-INDENT: 2em"> �҂����Ć��}��Ӳ�P��linux���P(gu��n)������҂��ĺܶ�Ӳ�P�Q֧�ָ��NIDE�f(xi��)�h�汾��linux�(q��)�ӣ����nj��H������ֻ���������һЩ�ϲ��ܿɿ��Ĺ�����������������f(xi��)�h�汾��������������Ӳ�P�����(sh��)��r�¶����Թ���������������Еr���@�N��һ��ʹ���(q��)�Ӻ̓�(n��i)����Ӳ�P��B(t��i)�Ϯa(ch��n)������������ڃ�(n��i)�˵Ć��}���@������(d��o)��(sh��)��(j��)��ĬĬ����Ⱦ����@�����}ʹ���҂�ʹ��У�́�z�y��(sh��)��(j��)��Ⱦ��������F(xi��n)�@�N��r�����҂�����Ҫ�ă�(n��i)�ˁ�̎���@�N�f(xi��)�h��һ�µ���r������</P>
<P style="TEXT-INDENT: 2em">֮ǰ������linux2.2��(n��i)�˵�fsync()�Ļ��M������҂�Ҳ�����^һЩ���}���������Ļ��M���c�ļ���С�����DZ��IJ��ֵĴ�С���P(gu��n)�ġ��@�����҂���IJ�����־����һ�����}����������������҂����F(xi��n)�z���c֮ǰ����҂�ͨ�^����ͬ�������@�^���@�����}������w�Ƶ�Linux2.4����Q����������</P>
<P style="TEXT-INDENT: 2em"> ��һ������linux�a(ch��n)���Ć��}���c�x���i���P(gu��n)�ġ���һ����ַ���g��ľ����ڏ�Ӳ�P���x퓔�(sh��)��(j��)(�x�i)������mmap�{(di��o)�����ĵ�ַ���g(���i)�ĕr�������횳���һ���x���i���������ϵ�y(t��ng)ؓ�d�ܸ�����a(ch��n)���YԴƿ�i���߳��F(xi��n)Ӳ��ʧ���r���҂�������˲�B(t��i)�ij��r�������҂��l(f��)�F(xi��n)��(d��ng)�űP�x������̎��ǰ��ӳ��Ĕ�(sh��)��(j��)�r��������@���i�����˾W(w��ng)�j(lu��)���̌��µĔ�(sh��)��(j��)ӳ�䵽��(n��i)�档�����҂��Ĺ���ƿ�i��Ҫ���ھW(w��ng)�j(lu��)���������ǃ�(n��i)�控�����������҂�ͨ�^ʹ��pread()�����~����_�N���mmap()�@�^���@�����}���</P>
<P style="TEXT-INDENT: 2em"> �M�ܳ��F(xi��n)��һЩ���}�����linux���a�Ŀ����Ԏ������҂�̽��������ϵ�y(t��ng)���О����������m��(d��ng)?sh��)ĕr�C�����҂�Ҳ�����M��(n��i)�˲��c�_Դ��^(q��)�����@Щ׃�������</P>
<P style="TEXT-INDENT: 2em"> 8.���P(gu��n)����</P>
<P style="TEXT-INDENT: 2em">�������Ĵ��ͷֲ�ʽ�ļ�ϵ�y(t��ng)����AFS������GFS�ṩ��һ�����صĪ������ֿ��g���ʹ�Ô�(sh��)��(j��)���Ԟ������e����ؓ�dƽ��������Ƅӡ����cAFS��ͬ������������������w�����ܺ����e������GFS���ļ���(sh��)��(j��)�ڶ����惦����(w��)���ϴ惦�������@�c�������xFS����Swift���</P>
<P style="TEXT-INDENT: 2em"> Ӳ�P���������˵�����������c��(f��)�s��RAID��������������������Ը����������������GFS��ȫ���ø��������M���������������xFS����Swift���ĸ����ԭʼ�惦������</P>
<P style="TEXT-INDENT: 2em">�cAFS,xFS,Frangipani,Intermezzo�@Щϵ�y(t��ng)��ȣ�GFS���ļ�ϵ�y(t��ng)�ӿ��²����ṩ�κξ�����������҂���Ŀ�˹���ؓ�d��͌���ͨ���ĆΑ�(y��ng)�ó����\��ģʽ���f��������������Dz������õ���������@�Nģʽͨ����Ҫ�xȡ������(sh��)��(j��)���ϻ����������M���S�C��seek������ÿ��ֻ�x�����Ĕ�(sh��)��(j��)�������</P>
<P style="TEXT-INDENT: 2em">һЩ�ֲ�ʽ�ļ�ϵ�y(t��ng)����xFS,Frangipani,Minnesota��s GFS��GPFS�h�����������(w��)��(ji��)�c��������ه�ڷֲ�ʽ���㷨�M��һ���Ժ������҂��x�����뻯�y���Ǟ��˺����O(sh��)Ӌ���ӿɿ��������@ȡ�`��������������������һ�����뻯��master�������F(xi��n)��(f��)�s��chunk���ú͂�ݲ��ԣ����master���дֵ����P(gu��n)��Ϣ�Լ������������ĸ�׃�������҂�ͨ�^master��B(t��i)��С�Լ��������C�����M�Ђ�݁���Q���e����(d��ng)ǰͨ�^Ӱ��master�C���ṩ�ɔUչ�ԺͿ����������������master��B(t��i)�ĸ��£�ͨ�^append��write-ahead ��־���M�г־û������������҂�����ͨ�^�����Harp�����copyģʽ���ṩһ�����҂���(d��ng)ǰģʽ���и���һ���Եĸ߿�����������</P>
<P style="TEXT-INDENT: 2em"> �҂�δ�팢��Q�����Lustre��һ�����}�������͑��˵����w���ܡ�Ȼ���҂�ͨ�^��ע���҂��Լ�����������ǘ�(g��u)��һ��POSIX�����ļ�ϵ�y(t��ng)���������@�����}����������������GFS���ٲ��ɿ��M���Ĕ�(sh��)���Ǻܴ���������������e���҂��O(sh��)Ӌ������������</P>
<P style="TEXT-INDENT: 2em"> GFS�������NASD�ܘ�(g��u)����������NASD�ǻ��ھW(w��ng)�j(lu��)�B�ӵ�Ӳ�P�(q��)������GFS�tʹ����ͨ�C������chunkserver�������cNASD��ͬ��chunkserver����Ҫ�r����̶���С��chunk���������]��ʹ��׃�L����������GFS߀���F(xi��n)���T����ƽ����������������a(ch��n)Ʒ�h(hu��n)����Ҫ�Ŀ��ٻ֏�(f��)������</P>
<P style="TEXT-INDENT: 2em"> ����Minnesota��s GFS��NASD��������҂����]�Ќ����׃�惦�O(sh��)���ģ���������҂�����ע�ڽ�Qʹ�ìF(xi��n)����Ʒ���M���M�ɵď�(f��)�s�ֲ�ʽϵ�y(t��ng)���ճ��Ĕ�(sh��)��(j��)̎������������</P>
<P style="TEXT-INDENT: 2em"> ͨ�^�����a(ch��n)�����M�������ʹ��ԭ��record append������Q���c�ֲ�ʽ����ϵ�y(t��ng)River����Ɔ��}����Riverʹ�û��ڃ�(n��i)��Ŀ�C���ֲ�ʽ����Լ�С�ĵĔ�(sh��)��(j��)�����Ɓ���Q�@�����}��������GFSֻʹ����һ�����Ա��ܶ����a(ch��n)��append��(sh��)��(j��)���ļ���Riverģ��֧��m to n�ķֲ�ʽ������������ȱ�����e����GFSĿǰֻ֧��m to 1����������M�߿����xȡ��ͬ�ļ���������������횅f(xi��)�{(di��o)�Ì�ݔ��ؓ�d�M�Є���(����̎�����ཻ��һ����)�����</P>
<P style="TEXT-INDENT: 2em"> 9.���Y(ji��)</P>
<P style="TEXT-INDENT: 2em">GFS��������Щ����Ʒ��Ӳ����֧�ִ�Ҏ(gu��)ģ��(sh��)��(j��)̎���ı�Ҫ��������M��ijЩ�O(sh��)Ӌ�Q���c�҂�����đ�(y��ng)��������P(gu��n)����������ǿ��ԑ�(y��ng)���ھ����������������Ĕ�(sh��)��(j��)̎���΄�(w��)�С�</P>
<P style="TEXT-INDENT: 2em"> ᘌ��҂���(d��ng)ǰ�đ�(y��ng)��ؓ�d�������҂�����ҕ���y(t��ng)���ļ�ϵ�y(t��ng)��һЩ���O(sh��)���҂��Č�ҕ�������ʹ���҂����O(sh��)Ӌ�Юa(ch��n)����һЩ�c֮������ͬ���^�c������҂����M��ʧ���������B(t��i)�����Ǯ������齛(j��ng)���M�е��ڴ��ļ��ϵ�append�M�Ѓ�(y��u)�������Ȼ�����x(ͨ��������)���������˸��M����ϵ�y(t��ng)�҂��Uչ���ҷ����˘˜��ļ�ϵ�y(t��ng)�ӿ�������</P>
<P style="TEXT-INDENT: 2em"> �҂���ϵ�y(t��ng)ͨ�^�O(ji��n)�أ�����P(gu��n)�I��(sh��)��(j��)���������ٺ��Ԅӻ֏�(f��)���ṩ���e��Chunk���ʹ���҂���������chunkserver��ʧ������@Щ��(j��ng)���Ե�ʧ�����(q��)����һ����(y��u)�ŵ��ھ��ޏ�(f��)�C�ƵĮa(ch��n)�����������Ե������M���ޏ�(f��)�M��Ļ֏�(f��)��Щ�Gʧ�ĸ�����������������҂�ͨ�^ʹ��У�́�z�y��(sh��)��(j��)�p��������(d��ng)ϵ�y(t��ng)��Ӳ�P��(sh��)Ŀ�ܴ�ĕr���������@�N�p��׃�ú��������</P>
<P style="TEXT-INDENT: 2em"> �҂����O(sh��)Ӌ���F(xi��n)�ˌ��ںܶ���(zh��)�д����΄�(w��)�IJ��l(f��)�x�ߺ͌��ߵĸ������ʡ�ͨ�^�Ĕ�(sh��)��(j��)��ݔ�з��x�ļ�ϵ�y(t��ng)������������҂��팍�F(xi��n)�@��Ŀ���������master��̎���ļ�ϵ�y(t��ng)������������(sh��)��(j��)��ݔ�tֱ����chunkserver�Ϳ͑���֮�g�M�С�ͨ�^����chunk�Ĵ�С�Լ�chunk����s�C��������������master����ͨ�����еą��c��������@ʹ�����master�����ɞ�ƿ�i��������҂������ڮ�(d��ng)ǰ�W(w��ng)�j(lu��)�f(xi��)�h���ϵĸ��M�����ṩ�͑��ˌ������ʵ����ơ�</P>
<P style="TEXT-INDENT: 2em"> GFS�ɹ��؝M�����҂��Ĵ惦���������ͬ�r��������a(ch��n)Ʒ��(sh��)��(j��)̎��ƽ�_������߀�����аl(f��)�Ĵ惦ƽ�_�����V��ʹ����������һ��ʹ�҂����Գ��m(x��)��(chu��ng)���Լ��挦����web�ĺ�����(sh��)��(j��)����(zh��n)����Ҫ��������</P>
<P style="TEXT-INDENT: 2em">���x</P>
<P style="TEXT-INDENT: 2em">����</P></DIV>
<DIV>�����D(zhu��n)�ԣ�<A href="http://duanple.blog.163.com/blog/static/7097176720109145829346/" target=_blank>http://duanple.blog.163.com/blog/static/7097176720109145829346/</A></DIV>
<DIV> </DIV>
<DIV>Ӣ��ԭ�ĵ�ַ�� <A href="http://labs.google.com/papers/gfs.html" target=_blank>http://labs.google.com/papers/gfs.html</A></DIV>
<DIV>��Ӣ��ԭ�����d��<A href="http://blog.chinaunix.nethttp://blog.chinaunix.net/attachment/attach/25/09/82/9825098298af6ea9b7157fa5a93eb709731a8a577c.pdf" target=_blank><IMG src="http://blog.chinaunix.net/blog/image/attachicons/common.gif" align=absMiddle border=0> gfs-sosp2003.pdf </A> </DIV>
<DIV> </DIV> |
|
 ���Mע��
���Mע��






 �l(f��)���� 2011-12-19 13:54
�l(f��)���� 2011-12-19 13:54